基础
运算函数
| 函数 | 作用 | 例 |
|---|---|---|
| abs(x) | 绝对值函数 | abs(-1) = 1 |
| divmod(x,y) | 商余函数 | divmod(10,3) = (3,1) |
| pow(x,y,z) | 幂运算函数 | pow(2,2) = 4,pow(2,2,3) = 1 |
| round(x) | 四舍五入函数 | round(1.5) = 2 |
| max(x) | 最大值函数 | max(1,2,3) = 3 |
| min(x) | 最小值函数 | min(1,2,3) = 1 |
字符串处理函数
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度,len(“壹1,\‘ a”) = 6 |
| str(x) | 任意类型x所对应的字符串形式,str(‘abc123’)=abc123,与eval()形成对比 |
| hex(x)或oct(x) | 整数x的十六进制或八进制小写形式的字符串,hex(111)=’0x6f’,oct(111)=’0o157’ |
| chr(x) | x为Unicode编码,返回其对应的字符,chr(20197) = ‘以’ |
| ord(x) | x为字符,返回其对应的Unicode编码,ord(“以”) = 20197 |
输入为小数字符串,转换成int型方法:
a = int(float(a))
for i in range(12):
print(chr(9800 + i),end='')♈♉♊♋♌♍♎♏♐♑♒♓
字符串处理方法
| 方法及使用 | 描述 |
|---|---|
| str.lower()或str.upper() | 返回字符串的副本,全部字符小写/大写 “AbCdEfGh”.lower()结果为“abcdefgh” |
| str.split(sep=None) | 返回一个列表,由str根据sep被分隔的部分组成 “A,B,C”.split(“,”)结果为[‘A’,’B’,’C’] |
| str.count(sub) | 返回子串sub在str中出现的次数 “a apple a day”.count(“a”)结果为4 |
| str.replace(old,new) | 返回字符串str副本,所有old子串被替换为new “python”.replace(“n”,”n123”)结果为‘python123’ |
| str.center(width[,fillchar]) | 字符串str根据宽度width居中fillchar可选 “python”.center(20,”=”) 结果为‘=======python=======’ |
| str.strip(chars) | 从str中去掉在其左侧和右侧chars中列出的字符 “= python=”.strip(“ =np”)结果为 ‘ytho’ |
| str.join(iter) | 在iter变量除最后元素外每个元素后增加一个 str”,”.join(“12345”)结果为’1,2,3,4,5’ 主要用于字符串分隔等 |
| str.isdigit() | 判断接收的字符是否为数字,返回True或False,无参数 |
异常处理
即程序报错执行except的语句


异常类型详见:Python 异常处理
随机数函数
| 函数 | 描述 |
|---|---|
| randint(a,b) | 生成一个[a,b]之间的整数>>>random.randint(10,100)=64 |
| randrange(m,n[,k]) | 生成一个[m,n)之间以k为步长的随机整数>>>random.randrange(10,100,10)=80 |
| getrandbits(k) | 生成一个k比特长的随机整数>>>random.getrandbits(16)=37885 |
| uniform(a,b) | 生成一个[a,b]之间的随机小数>>>random.uniform(10,100)=13.234563456 |
| choice(seq) | 从序列seq中随机选择一个元素>>>random.choice([1,2,3,4,5,6,7,8,9,0])=5 |
| shuffle(seq) | 将序列seq中元素随机排序,返回打乱后的序列 >>>s=[1,2,3,4];random.shuffle(s);print(s) [3,1,4,2] |
global:在函数内部声明全局变量
递归
阶乘:
def a(x):
if x == 1: return 1
return (x * a(x-1))求和
def a(x):
if x == 1: return 1
return (x + a(x-1))汉诺塔问题求解
count = 0
def hanoi(n,src,dst,mid):
global count
if n == 1:
print("{}:{}->{}".format(1,src,dst))
count += 1
else:
hanoi(n-1,src,mid,dst)
print("{}:{}->{}".format(n,src,dst))
count += 1
hanoi(n-1,mid,dst,src)
hanoi(5,'A','B','C')
print(count)科赫曲线雪花绘制
import turtle
def koch(size,n):
if n == 0:
turtle.fd(size)
else:
for angle in [0,60,-120,60]:
turtle.left(angle)
koch(size/3,n-1)
def main():
turtle.setup(1200,800)
turtle.penup()
turtle.goto(-300,100)
turtle.pendown()
turtle.pensize(2)
for i in range(3):
koch(300,3) #2阶科赫曲线,阶数
turtle.right(120)
turtle.hideturtle()
turtle.done()
main()集合处理方法
| 操作函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果x不在集合S中,将x增加到S |
| S.discard(x) | 移除S中元素x,如果不在集合S中,不报错 |
| S.remove() | 移除S中元素x,如果x不在集合S中,产生KeyError异常 |
| S.clear() | 移除S中的所有元素 |
| S.pop() | 随机返回S中的一个元素,更新S,若S为空产生KeyError异常 |
| S.copy() | 返回集合S中的一个副本 |
| len(S) | 返回集合S的元素个数 |
| x in S | 判断S中元素x,x在集合S中,返回True,否则返回False |
| x not in S | 判断S中元素x,x不在集合S中,返回False,否则返回True |
set(x) |
将其他类型变量x转变为集合类型,可用以集合元素去重 |
list(x) |
转换为列表类型 |
tuple(x) |
转换为元组类型 |
序列
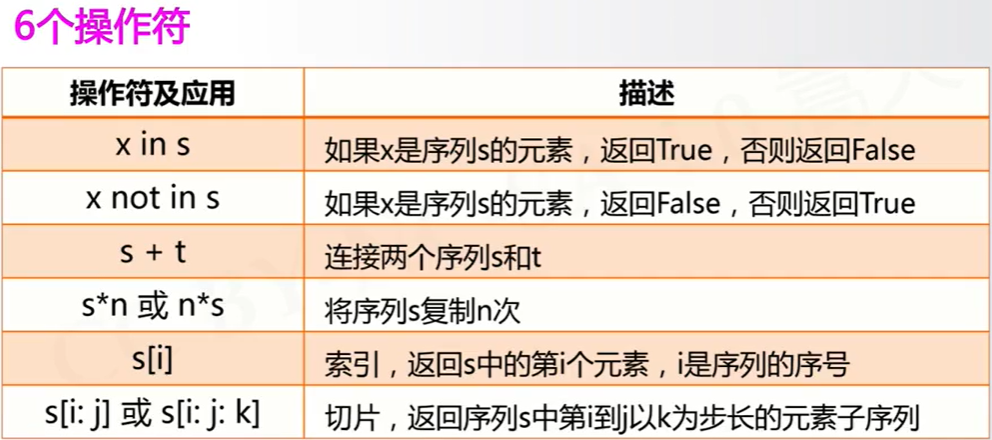
| 函数和方法 | 描述 |
|---|---|
| len(s) | 返回序列s的长度 |
| min(s) | 返回序列s的最小元素,s中元素需要可比较 |
| max(s) | 返回序列s的最大元素,s中元素需要可比较 |
| s.index(x)或s.index(x,i,j) | 返回序列s从i开始到j位置中第一次出现元素x的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
列表

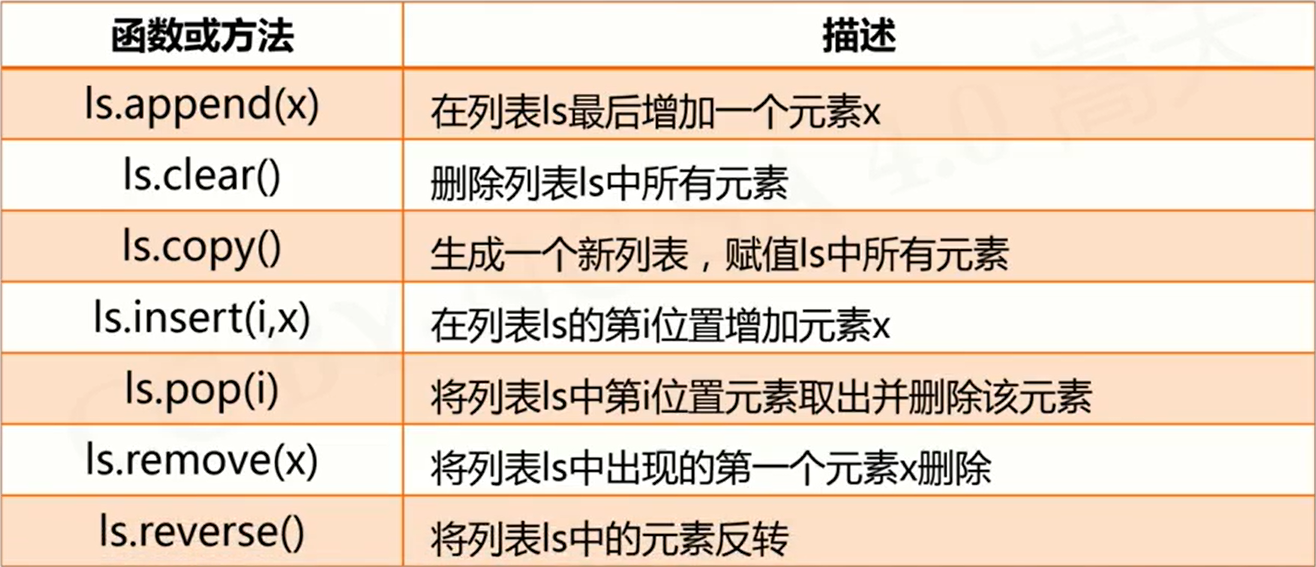
sorted():对列表进行排序(小到大)
字典
使用{}和dict{}给变量赋值创建,键值对之间用:分隔,d[key]可以进行索引也可用于赋值,但在进行赋值的时候只能啊a[1] = a[2]这样赋值,不能1 = a[1]、a[i]代表的是i这个键对应的值,无法直接修改值的键,如果要对键操作需要将这个键删除(即(del a[i])),然后再将这个值赋给一个新的键。
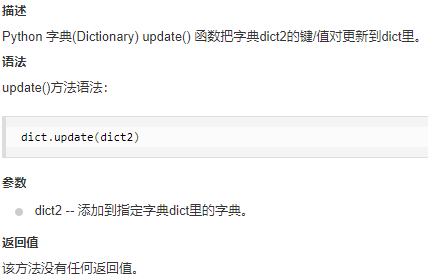
update()方法,在字典中添加键值对,也可以直接赋值添加


文件

文件读取方法:read(),readline(),readlines(),在入方法:write(),writelines()
二维数据的处理:for循环+.split()和.join()
三国演义人物出场词频统计
import jieba
txt = open("三国演义.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt) #lcut精确模式,返回一列表类型
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1 #字典类型中'='为创造一个键值对,亦可进行赋值操作
items = list(counts.items()) #items方法为返回字典中所有的键值对信息
items.sort(key = lambda x:x[1],reverse=True)
for i in range(20):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))yield
生成器参考

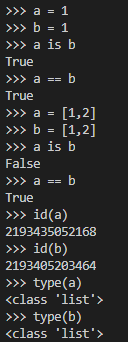
is
在Pytohn中,进行数值比较时会用到 == 运算符,判断两个变量的地址是否相同用 is 关键字
如下列比较操作
pass
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
def sample(n_samples):
pass该处的 pass 便是占据一个位置,因为如果定义一个空函数程序会报错,当你没有想好函数的内容是可以用 pass 填充,使程序可以正常运行。
u,r,b,f
在字符串前面为了能够更好的识别字符串处理方式,于是在字符串前面加上这些标识符来识别
- u:后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
- r:去掉反斜杠的转义机制。常用于re模块
- b:后面字符串是bytes 类型。在网络编程中,服务器和浏览器只认bytes 类型数据。
- f:字符串内支持大括号内的python 表达式
*和**
这两种用法可以将任意个数的参数导入到python函数中
单星号(*):*agrs 将所有参数以元组(tuple)的形式导入,如下:
def a(str1,*str2):
print(str1)
print(str2)
def b(str1,str2):
print(str1)
print(str2)
k = [1,2]
a(1,2,3,4,5,6,7)
b(*k) #解压参数列表输出:
1
(2, 3, 4, 5, 6, 7)
1
2双星号(**):**kwargs 将参数以字典的形式导入,如下:
def a(str1,**str2):
print(str1)
print(str2)
a(1,a=2,b=3)输出:
1
{'a': 2, 'b': 3}内置函数
eval()
评估函数
用法:去掉参数最外侧引号并执行余下语句的函数

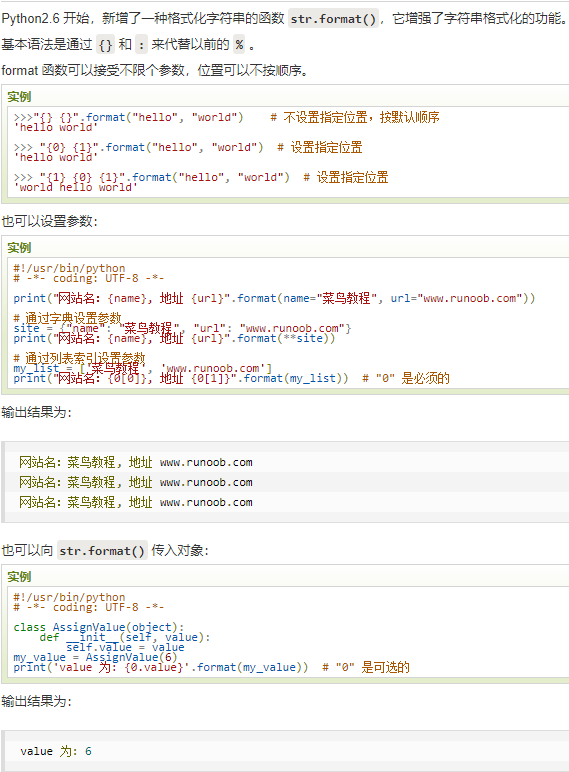
format()
格式化函数
基本语法是通过{}和:来代替以前的%,详

id()
id() 函数返回对象的唯一标识符,标识符是一个整数。
CPython 中 id() 函数用于获取对象的内存地址。
语法:id([object])

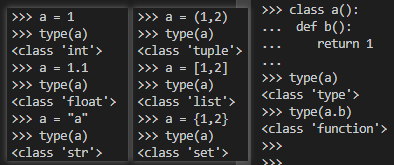
type()

isinstance()

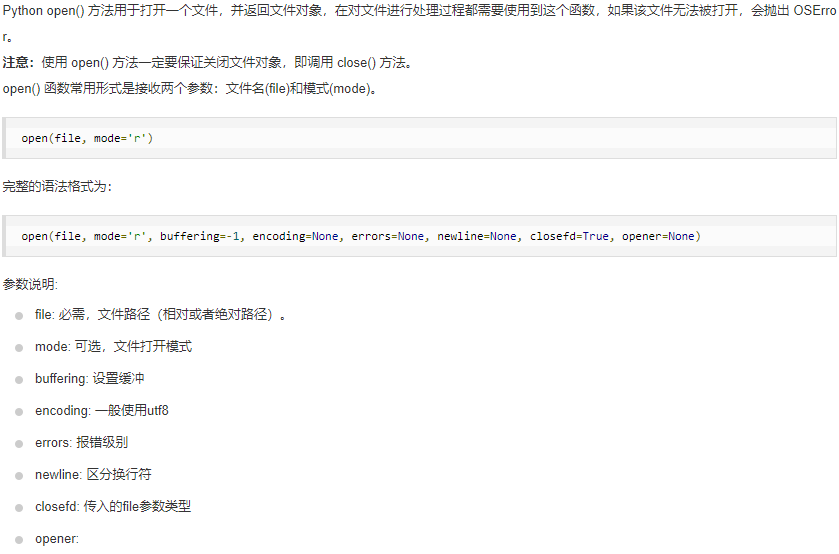
open()
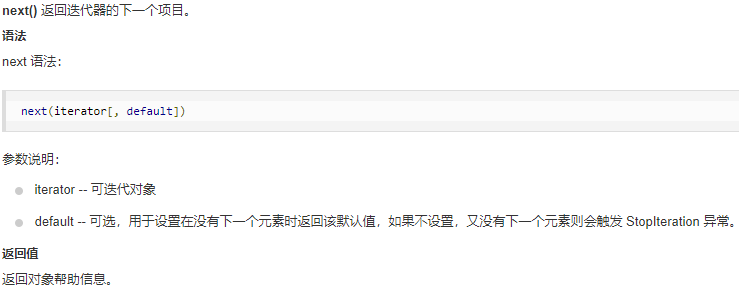
next()
send()
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | file.read([size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size])读取整行,包括 “\n” 字符。 |
| 8 | file.readlines([sizeint])读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 9 | file.seek(offset[, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | file.truncate([size])截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
一些库
OS
OS库路径操作




os.path.getsize(path):返回path对应文件的大小,以字节为单位>>>os.path.getsize(“c:/1.txt”) ——> 123
OS库进程管理
os.system(command)———–执行程序或命令command,在Windows中返回值为cmd的调用返回信息
OS库环境参数

| 函数 | 描述 |
|---|---|
| os.getlogin() | 获得当前系统登录用户名称 |
| os.cpu_count() | 获得当前系统的CPU数量 |

wordcloud
配置对象参数—>加载词云文本—>输出词云文件
分隔:以空格分隔单词
统计:单词出现次数并过滤
字体:根据统计配置字号
布局:颜色环境尺寸
| 方法 | 描述 |
|---|---|
| w.generate(txt) | 向WordCloud对象w中加载文本txt >>>w.generate("Python and WordCloud") |
| w.to_file(filename) | 将词云输出为图像文件,.png或.jpg格式 >>>w.to_file("outfile.png") |
w.wordcloud.WordCloud()参数:
| 参数 | 描述 |
|---|---|
| min_font_size | 指定词云中字体的最小字体,默认4 >>>w=wordcloud.WordCloud(min_font_size=10) |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节 >>>w=wordcloud.WordCloud(max_font_size=20) |
| font_step | 指定词云中字体字号的步进间隔,默认为1 >>>w=wordcloud.WordCloud(font_step=2) |
| width | 指定词云对象生成图片的宽度,默认400像素 >>> w= wordcloud.WordCloud(width=600) |
| height | 指定词云对象生成图片的高度,默认200像素 >>>w= wordcloud.WordCloud(width=400) |
| font_path | 指定字体文件的路径,默认None >>> w=wordcloud.WordCloud(font_path=”msyh.ttc”) |
| max-words | 指定词云显示的最大单词数量,默认200 >>> w= wordcloud.WordCloud(max_words=20) |
| stop_word | 指定词云的排除列表,即不显示单词列表>>> w= wordcloud.WordCloud(stop_words={“Python”}) |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数>>>from scipy.misc import imread >>> mk = imread(“pic.png”) >>> w = wordcloud.WordCloud(mask=mk) |
| background_color | 指定词云图片的背景颜色,默认为红黑色 >>> w= wordcloud.WordCloud(background_color=”white”) |
PyInstaller
打包.py文件为.exe应用程序
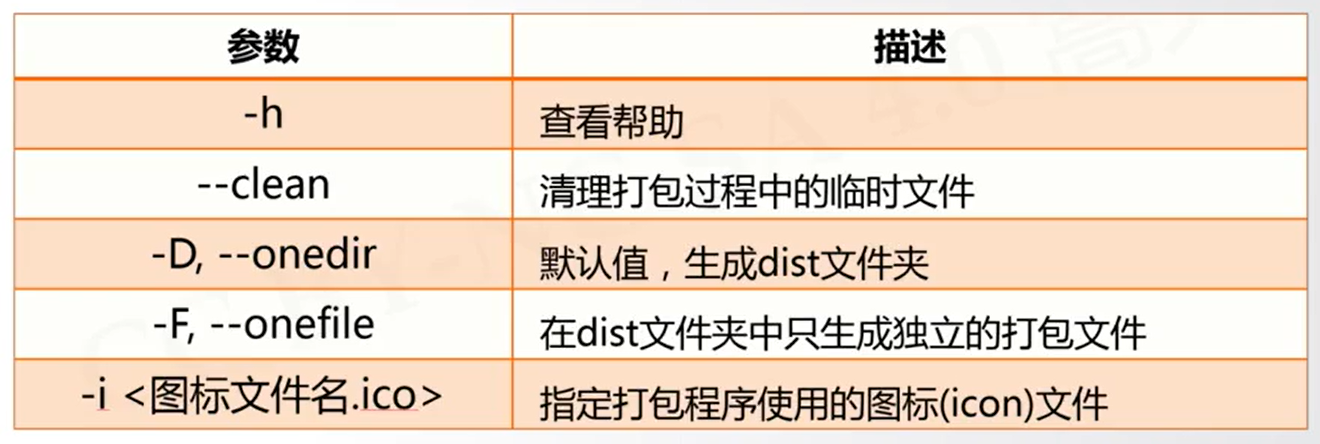
pip
| 使用方法 | 功能 |
|---|---|
| pip install <第三方库名> | 安装第三方库 |
| pip install -U <第三方库名> | 更新第三方库 |
| pip uninstall <第三方库名> | 卸载第三方库 |
| pip download <第三方库名> | 下载但不安装指定的第三方库 |
| pip show <第三方库名> | 列出某个指定第三方库的详细信息 |
| pip search <关键字> | 根据关键词在名称和介绍中搜索第三方库 |
| pip list | 列出当前系统的python版本已经安装的第三方库 |
requests
主要方法
| 方法 | 说明 |
|---|---|
| requests.requset(method,url,**kwargs) | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get(url,params=None,**kwargs) | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head(url,**kwargs) | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post(url,data=None,json=None,**kwargs) | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put(url,data=None,**kwargs) | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch(url,data=None,**kwargs) | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete(url,**kwargs) | 向HTML页面提交删除请求,对应于HTTP的DELETE |
method:
请求方式,GET,HEAD,POST,PUT,PATCH,DALETE,OPTIONS
**kwargs:
控制访问的参数,均为可选项
params:字典或字节序列,作为参数增加到url中
data:字典、字节序列或文件对象,作为Request的内容
json:JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头
cookies:字典或CookieJar,Request中的cookie
auth:元祖,支持HTTP认证功能
files:字典类型,传输文件
timeout:设定超时时间,秒为单位
proxies:字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects:True/False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败,拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | url缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
Response对象属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出响应内容编码的方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
Beautiful Soup
也叫beautifulsoup4或bs4
基本元素

遍历方法
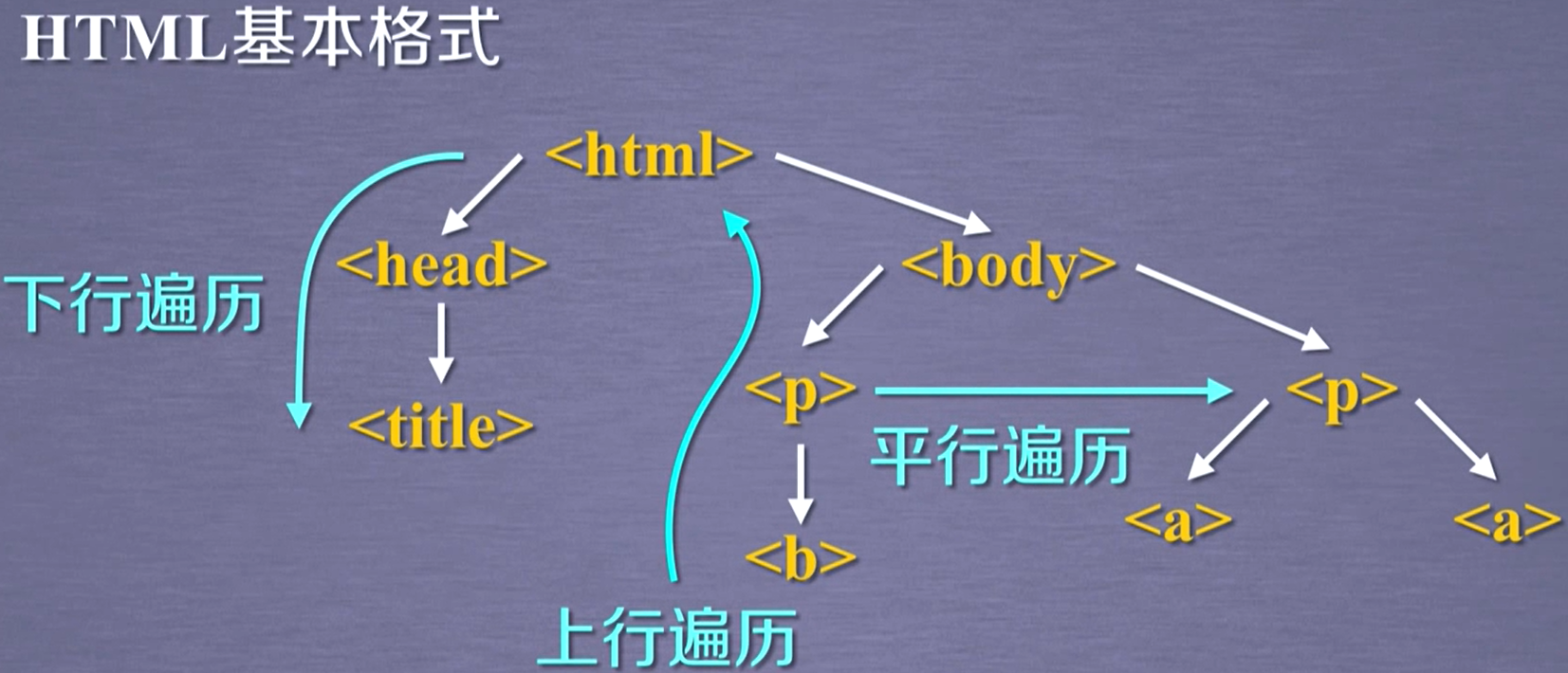



注:平行遍历发生在同一个父节点下的各节点间
prettify()格式化输出
内容查找方法


Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,’lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) | pip install html5lib |
re
匹配中文字符:[\u4e00-\u9fa5]
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))


compile函数

Match对象


最小匹配(非贪婪)

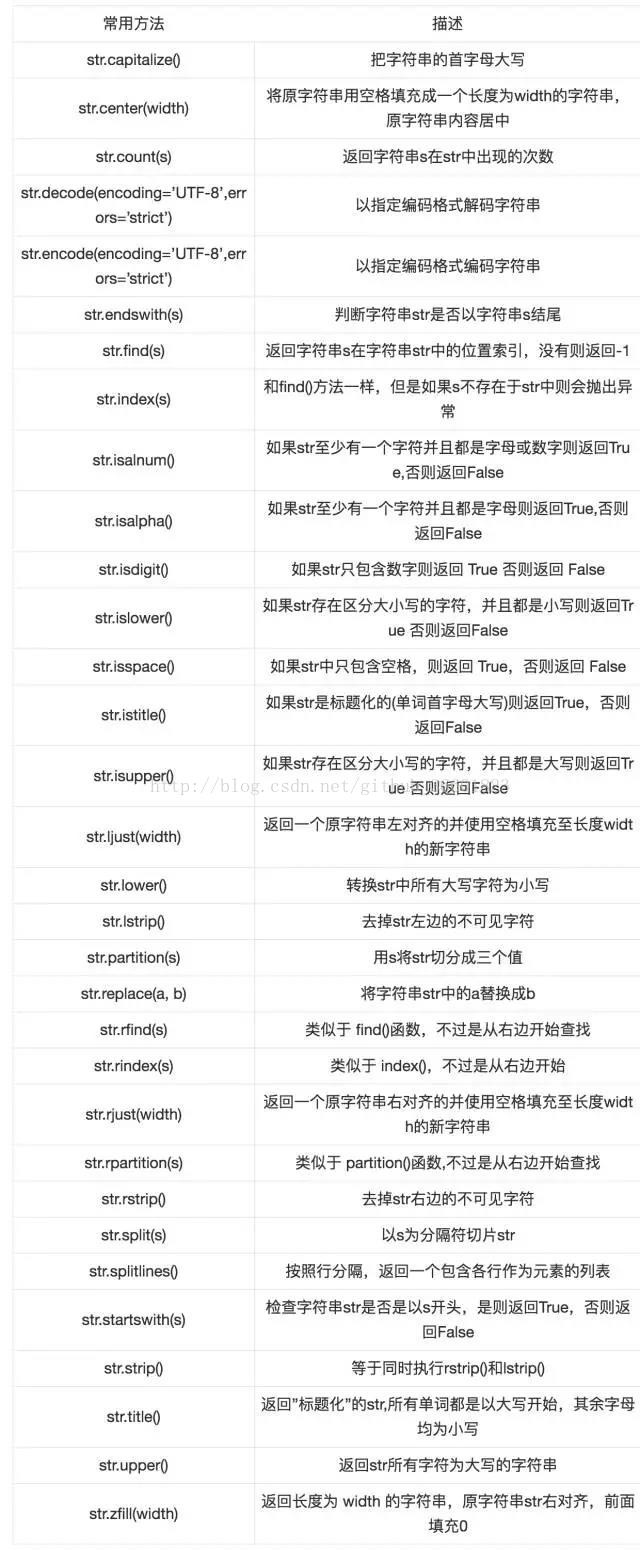
string

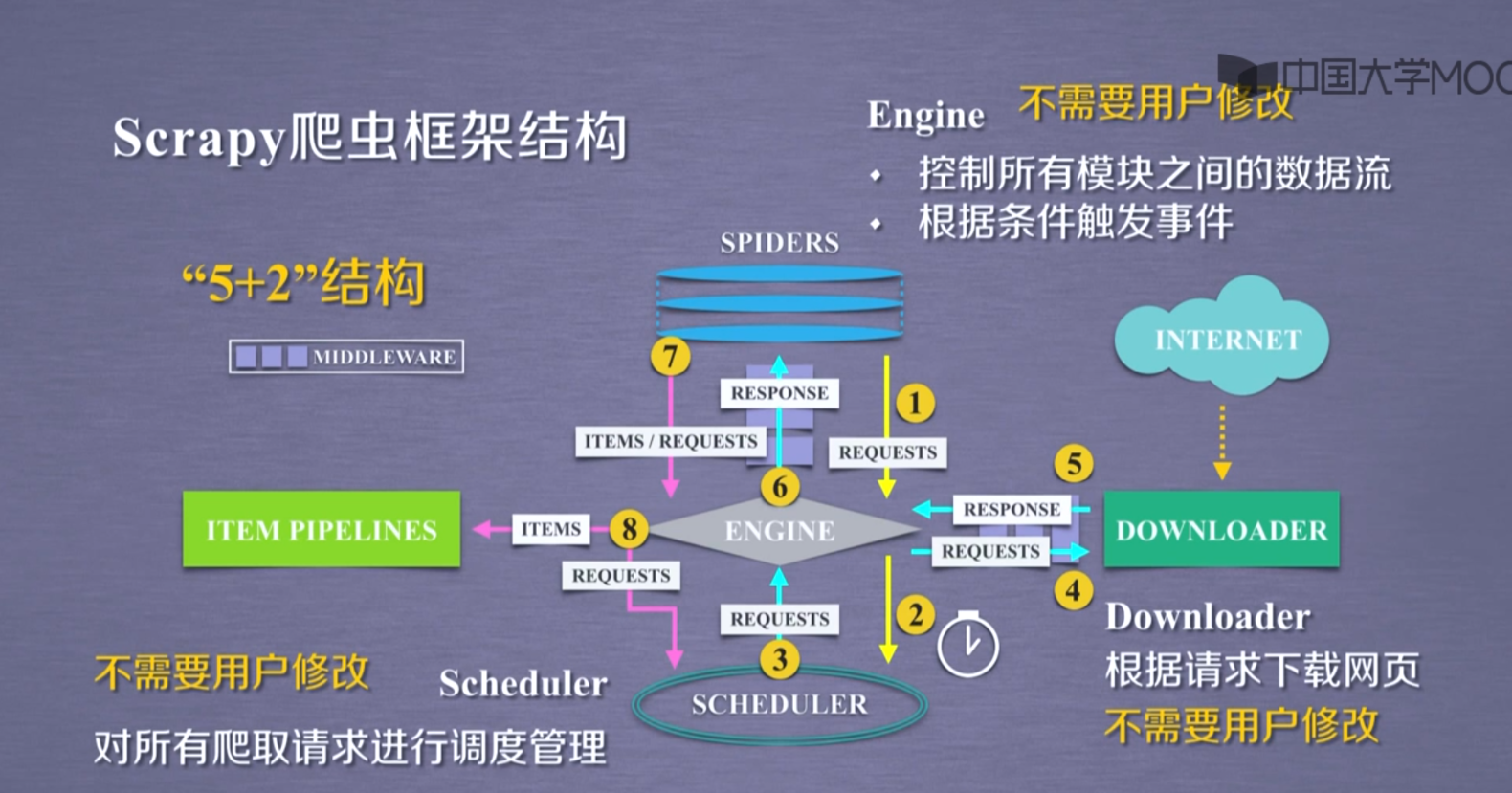
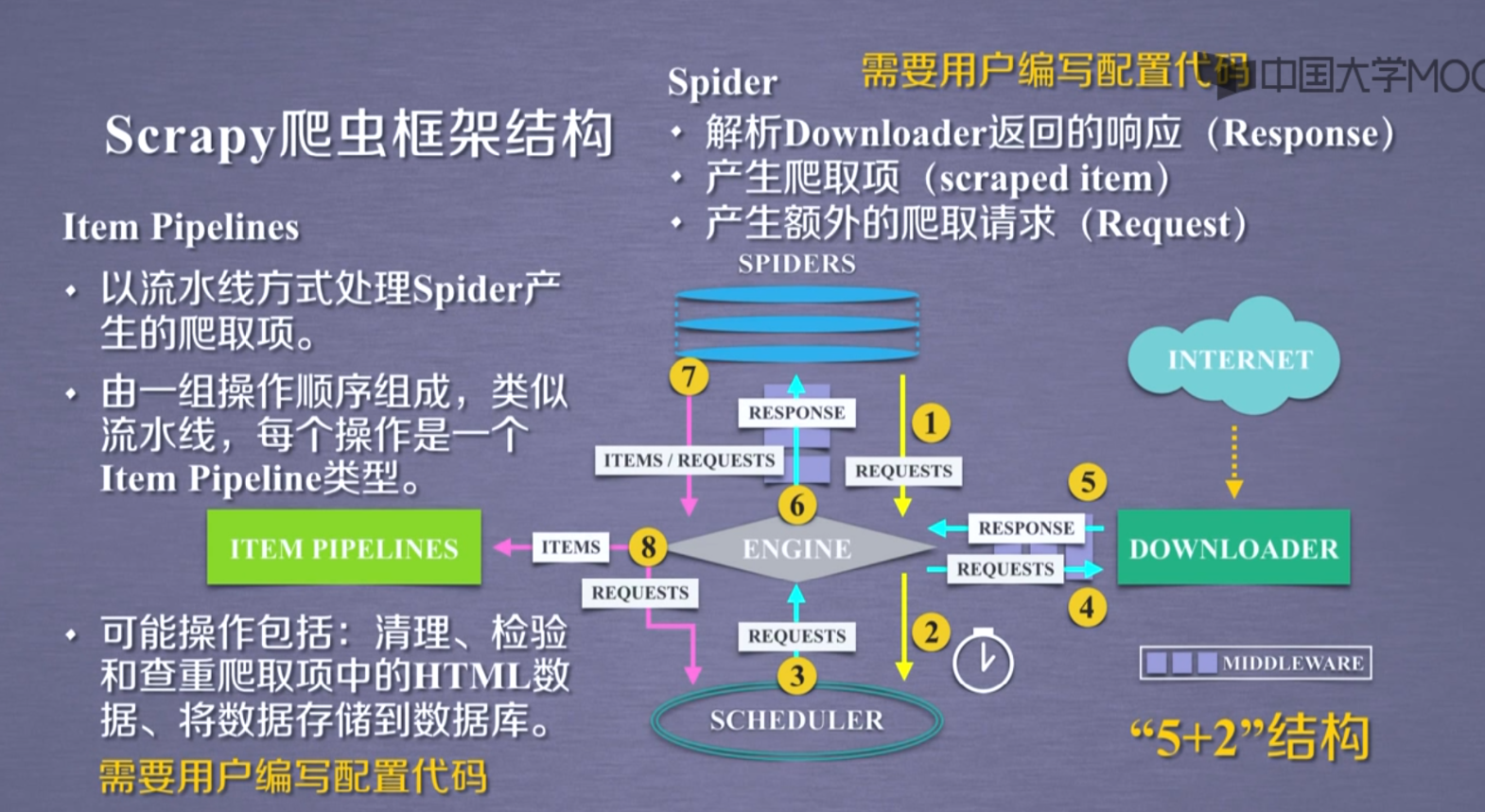
scrapy框架
主要结构


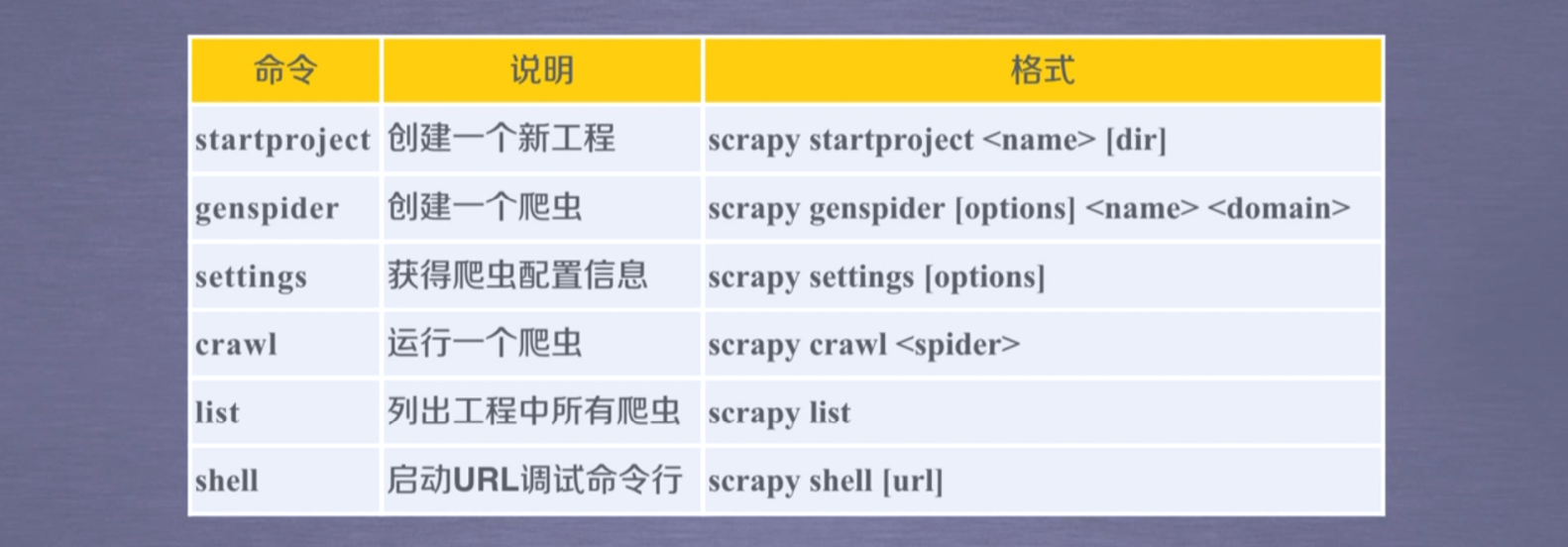
常用命令
工程目录

类
Request

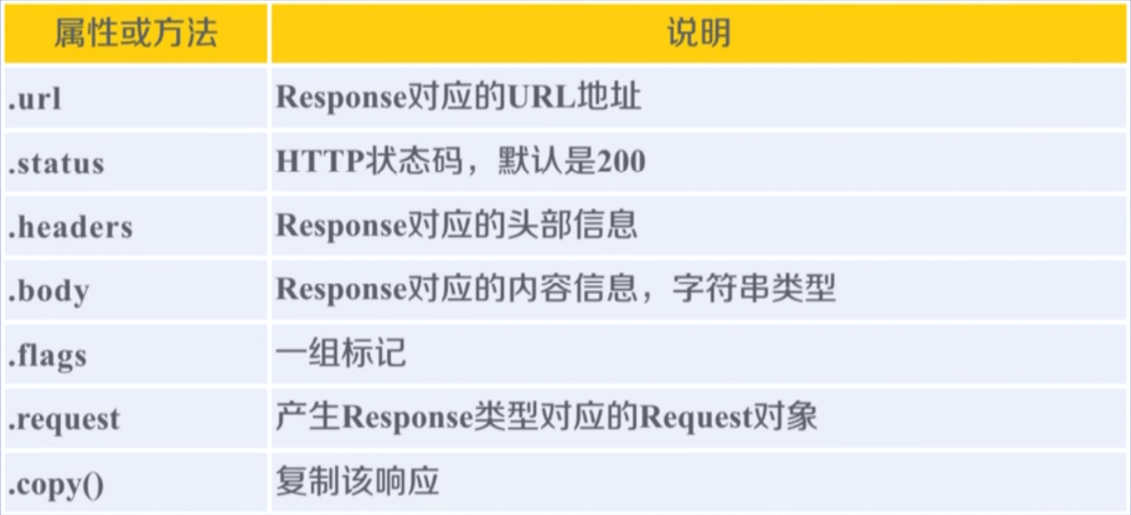
Response



若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues