threading模块
可用对象列表
| 对象 | 描述 |
|---|---|
| Thread | 表示一个执行线程的对象 |
| Lock | 锁原语对象 |
| RLock | 可重入锁对象,使单一的线程可以(再次)获得已持有的做(递归锁) |
| Condition | 条件变量对象,使得一个线程等待另一个线程满足的特定的”条件”,比如改变状态或某个数据值 |
| Event | 条件变量的通用版本,任意数量的线程等待某个事件的发生,在该事件发生后所有的线程将被激活 |
| Semaphore | 为线程间共享的有限资源提供了一个”计数器”,如果没有可用资源时会被阻塞 |
| BoundedSemaphore | 与Semaphore相似,不过它要在运行前等待一段时间 |
| Timer | 与Thread相似,不过它要在运行前等待一段时间 |
| Barrier | 创建一个”障碍”,必须达到指定数量的线程后才可以继续 |
Thread类
Thread类是threading模块主要的执行对象
Thread对象数据属性
| 属性 | 描述 |
|---|---|
| name | 线程名 |
| ident | 线程的标识符 |
| daemon | 布尔标志,表示这个线程是否是守护线程 |
Thread对象方法
| 属性 | 描述 |
|---|---|
__init__(group=None,target=None,name=None,args=(),kwargs={},verbose=None,daemon=None) |
实例化一个线程对象,需要有一个可调用的target,以及其参数args或kwargs |
| start() | 开始执行该线程 |
| run() | 定义线程功能的方法(通常在子类中被应用开发者重写) |
| join(timeout=None) | 直至启动的线程终止之前一直挂起;除非给出了timeout(秒),否则会一直阻塞 |
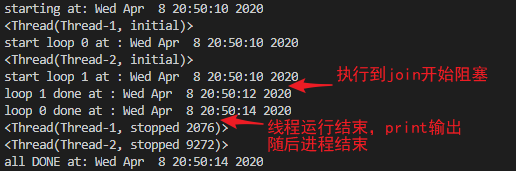
下面看一段可创建多线程的代码
import threading
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec):
print("start loop", nloop, "at :", ctime())
sleep(nsec)
print("loop", nloop, "done at :", ctime())
def main():
print("starting at:", ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = threading.Thread(target=loop, args=(i,loops[i])) #target=需要线程去执行的方法名 args=线程执行方法接收的参数,该属性是一个元组,如果只有一个参数也需要在末尾加逗号
threads.append(t)
for i in nloops:
print(threads[i])
threads[i].start() #线程等待启动
for i in nloops:
threads[i].join() # 线程等待,主线程不会等待子线程执行完毕再结束自身,可使用Thread类的join()方法来让所有子线程执行完毕以后,主线程再关闭
print(threads[i])
print("all DONE at:",ctime())
if __name__ == "__main__":
main()运行结果如下:
当然以上也可以创建多个线程,下面使用可调用的类来实现:
import threading
from time import ctime, sleep
loops = [4, 2]
class ThreadFunc(threading.Thread):
def __init__(self, func, args):
threading.Thread.__init__(self)
self.func = func
self.args = args
def run(self): #重写run方法,定义线程功能
self.func(*self.args)
def loop(nloop, nsec):
print('start loop', nloop, 'at :', ctime())
sleep(nsec)
print('loop', nloop, 'done at :', ctime())
def main():
print('starting at :', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = ThreadFunc(loop, (i, loops[i]))
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
print('all DONE at :',ctime())
if __name__ == "__main__":
main()效果和上面的一样,随后我们将其功能存储为一个独立的模块(myThread.py):
import threading
from time import ctime
class MyThread(threading.Thread):
def __init__(self,func,args,name = ""):
self.name = name
self.func = func
self.args = args
def getResult(self):
return self.res #将结果保存后通过getResult方法获取返回值
def run(self):
print("starting", self.name, ctime())
self.res = self.func(*self.args)
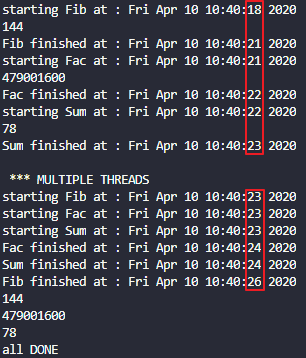
print(self.name, "finished at :", ctime())斐波那契,阶乘与累加
from myThread import MyThread
from time import ctime, sleep
def Fib(x):
sleep(0.005)
if x < 3: return 1
return (Fib(x - 1) + Fib(x - 2))
def Fac(x):
sleep(0.1)
if x < 2: return 1
return (x * Fac(x - 1))
def Sum(x):
sleep(0.1)
if x < 2: return 1
return (x + Sum(x - 1))
funcs = [Fib, Fac, Sum]
n = 8
def main():
nfuncs = range(len(funcs))
for i in nfuncs:
print("starting", funcs[i].__name__, "at :", ctime())
print(funcs[i](n))
print(funcs[i].__name__, "finished at :", ctime())
print("\n *** MULTIPLE THREADS")
threads = []
for i in nfuncs:
t = MyThread(funcs[i], (n,), funcs[i].__name__)
threads.append(t)
for i in nfuncs:
threads[i].start()
for i in nfuncs:
threads[i].join()
print(threads[i].getResult())
print("all DONE")
if __name__ == "__main__":
main()运行结果如下,可见多线程处理的效果
锁示例
from atexit import register
from random import randrange
from threading import Thread , Lock, current_thread
from time import ctime, sleep
class CleanOutputSet(set):
def __str__(self): #当使用print输出对象的时候,若定义了__str__(self)方法,打印对象时就会从这个方法中打印出return的字符串数据
return ", ".join(x for x in self)#表示将self中每个元素(除最后一个)后加上, 分离形成字符串后返回
lock = Lock() #创建一个锁对象
loops = (randrange(2,5) for x in range(randrange(3,7)))#此行表示随机选取2-5的数字随机选3-7次
remaining = CleanOutputSet()
def loop(nsec):
myname = current_thread().name #返回当前Thread对象的名字
lock.acquire() #加锁
remaining.add(myname) #add方法,如果不在集合中则添加
print("[{}] Started {}".format(ctime(),myname))
#print(" (remaining: {})".format(remaining or "NONE"))
lock.release() #释放
sleep(nsec)
lock.acquire()
remaining.remove(myname)
print("[{}] Competed {} ({} secs)".format(ctime(),myname,nsec))
print(" (remaining: {})".format(remaining or "NONE"))
lock.release()
def main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register #通过装饰器使用register,atexit模块使用register函数用于在 python 解释器中注册一个退出函数,这个函数在解释器正常终止时自动执行
def _atexit():
print("all DONE at :{}".format(ctime()))
if __name__ == "__main__":
main()输出结果之一如下:

I/O和访问相同的数据结构都属于临界区,因此需要多个锁来防止多个线程同时进入临界区
信号量示例
from atexit import register
from random import randrange
from threading import BoundedSemaphore, Lock, Thread
from time import ctime, sleep
lock = Lock()
MAX = 5
candytray = BoundedSemaphore(MAX)
def refill():
lock.acquire()
print("Refilling candy...",end="")
try:
candytray.release() #释放信号量,使内部计数器增加一,可以唤醒等待的线程
except ValueError:
print("full, skipping")
else:
print("OK ",end="")
print("Remaining :{}".format(candytray._value))
lock.release()
def buy():
lock.acquire()
print("Buying candy...",end="")
if candytray.acquire(False): # 获取一个信号量,如果内部计数器大于零,则将其减一并立即返回True。如果为零,返回False
print("OK ",end="")
print("Remaining :{}".format(candytray._value))
else:
print("empty, skipping")
lock.release()
def producer(loops):
for i in range(loops):
refill()
sleep(randrange(3))
def consumer(loops):
for i in range(loops):
buy()
sleep(randrange(3))
def main():
print("starting at :{}".format(ctime()))
nloops = randrange(2,6)
print("THE CANDY MACHINE (full with {})!".format(MAX))
Thread(target=consumer, args=(randrange(nloops, nloops + MAX + 2),)).start()
Thread(target=producer, args=(nloops,)).start()
@register
def _atexit():
print("all DONE at :{}".format(ctime()))
if __name__ == "__main__":
main()acquire(blocking=布尔值,timeout=None)
- 本方法用于获得Semaphore
- blocking默认值是True,此时,如果内部计数器值大于0,则减一,并返回;如果等于0,则阻塞,等待其他线程调用release()以使计数器加1;本方法返回True,或无线阻塞
- 如果blocking=False,则不阻塞,如若获取失败,则返回False
- 当设定了timeout的值,最多阻塞timeout秒,如果超时,返回False。
release()
- 释放Semaphore,内部计数器加1,可以唤醒等待的线程
结果之一如下:
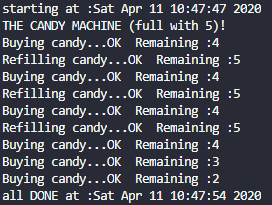
生产者,消费者(多线程)
queue模块
类
| 属性 | 描述 |
|---|---|
| Queue(maxsize=0) | 创建一个先入先出的队列,如果给定最大值,则在队列没有空间时阻塞,否则(未指定最大值),为无限队列 |
| LifoQueue(maxsize=0) | 创建一个后入先出的队列,如果给定最大值,则在队列没有空间时阻塞,否则(未指定最大值),为无限队列 |
| PriorityQueue(maxsize=0) | 创建一个优先级队列,如果给定最大值,则在队列没有空间时阻塞,否则(未指定最大值),为无限队列 |
异常
| 属性 | 描述 |
|---|---|
| Empty | 当对空队列调用get*()方法时抛出异常 |
| Full | 当对已满的队列调用put*()方法时抛出异常 |
方法
| 属性 | 描述 |
|---|---|
| qsize() | 返回队列大小(由于返回时队列大小可能被其它线程修改m,所以该值为近似值) |
| empty() | 如果队列为空,则返回True,否则返回False |
| full() | 如果队列已满,则返回True,否则返回False |
| put(item,block=True,timeout=None) | 将item放入队列,如果block为True(默认),且timeout为None,则在有可用空间之前阻塞,如果timeout为正值,则最多阻塞timeout秒,如果block为False,则抛出Empty异常 |
| put_nowait(item) | 和put(item,Flase)相同 |
| get(block=True,timeout-None) | 从队列中取得元素,如果给定了block(非0),则一直阻塞到有可用的元素为止 |
| get_nowait() | 和get(False)相同 |
| task_done() | 用于表示队列中的某个元素已执完成,该方法会被下面的join()使用 |
| join() | 在队列中所有元素执行完毕并调用上面的task_done()信号之前,保持阻塞 |
from time import sleep
from queue import Queue
from myThread import MyThread
def writeQ(queue):
queue.put("xxx",1)
print("producing object for Q... ",end="")
print("size now ",queue.qsize())
def randQ(queue):
val = queue.get()
print("consumed object from Q... size now ", queue.qsize())
def writer(queue, loops): #写数据入队列
for i in range(loops):
writeQ(queue)
def reader(queue, loops): #从队列中取出数据
for i in range(loops):
randQ(queue)
sleep(2) #添加延时便于观察
funcs = [reader, writer]
nfuncs = range(len(funcs))
def main():
nloops = 5
q = Queue(32)
threads = []
for i in nfuncs:
t = MyThread(funcs[i], (q, nloops), funcs[i].__name__)
threads.append(t)
for i in nfuncs:
threads[i].start()
for i in nfuncs:
threads[i].join()
print("all DONE")
if __name__ == "__main__":
main()
输出结果如下:

生产者,消费者(多进程)
multiprocessing模块方法参考python官方文档:multiprocessing — 基于进程的并行
from multiprocessing import Process, JoinableQueue
import time
import random
def consumer(q, name):
while True:
res = q.get() #从对列中取出并返回对象
time.sleep(random.randint(1, 3))
print('%s 吃掉了 %s' % (name, res))
q.task_done() #发送信号给q.join(),说明已经从队列中取走一个数据并处理完毕
def producer(q, name, food):
time.sleep(random.randint(1, 3))
res = '%s' % (food)
q.put(res) #将res放入队列
print('%s 生产了 %s' % (name, res))
q.join() # 等到消费者把自己放入队列中的所有的数据都取走之后,生产者才结束
if __name__ == '__main__':
q = JoinableQueue() # 使用JoinableQueue()
foods = ["包子","豆浆","油条","稀饭"]
producerthreads = []
consumerthreads = []
for i in range(len(foods)):
t = Process(target=producer, args=(q, '厨师', foods[i]))
producerthreads.append(t)
producerthreads[-1].start()
for i in range(len(foods)):
t = Process(target=consumer, args=(q, '吃货'))
consumerthreads.append(t)
consumerthreads[-1].daemon = True
consumerthreads[-1].start()
for i in range(len(producerthreads)):
producerthreads[i].join()
# 1、主进程等生产者p1,p2,p3结束
# 2、而p1,p2,p3,是在消费者把所有数据都取干净之后才会结束
# 3、所以一旦p1,p2,p3结束了,证明消费者也没必要存在了,应该随着主进程一块死掉,因而需要将生产者们设置成守护进程
print("END")输出结果如下:




若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues